

While ChatGPT has been receiving all the attention lately, OpenAI recently released yet another impressive model: Whisper. As OpenAI's blog post highlights, Whisper
...approaches human level robustness and accuracy on English speech recognition.
More specifically:
Whisper is an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual and multitask supervised data collected from the web.
Unlike GPT-3, OpenAI also open sourced the entire model open source, which you can find on GitHub here.
We won't get into the specifics of how Whisper works in this article as it's covered in their blog post, instead we're going to build a simple project combining Whisper and GPT-3 to understand its capabilities.
In particular, we're going to use Whisper & GPT-3 to take in a YouTube URL as input and output a summary. I've seen this idea elsewhere and it's definitely not that revolutionary, but credit is due to Andrew Wilkonson for this one:
Someone should build a GPT3 powered podcast summarizer.
— Andrew Wilkinson (@awilkinson) December 25, 2022
“Summarize the latest episode of HubermanLab”
And have it spit out key points and takeaways.
Aside from just summaries of YouTube videos, I've seen a number of other use cases for Whisper & GPT-3 such as turning YouTube videos into blog posts, being able to semantically search entire channels, and so on.
Before we get there, here are the steps we need to take to build our MVP:
- Transcribe the YouTube video using Whisper
- Prepare the transcription for GPT-3 fine-tuning
- Compute transcript & query embeddings
- Retrieve similar transcript & query embeddings
- Add relevant transcript sections to the query prompt
- Answer the query with relevant transcript context
- Summarizing the video with prompt engineering
For this project, I'll be summarizing this 60-minute interview with Elon Musk.
Also, if you want to see how you can use the Embeddings & Completions API to build simple web apps using Streamlit, check out our video tutorials below:
- MLQ Academy: Create a Custom Q&A Bot with GPT-3 & Embeddings
- MLQ Academy: PDF to Q&A Assistant using Embeddings & GPT-3
- MLQ Academy: Build a YouTube Video Assistant Using Whisper & GPT-3
- MLQ Academy: Build a GPT-3 Enabled Earnings Call Assistant
- MLQ Academy: Building a GPT-3 Enabled App with Streamlit
1. Transcribing YouTube videos with OpenAI Whisper
For step 1, we're going to use some of the code from this YouTube video on using Whisper for speech recognition.
First off, for this project we need to pip install the OpenAI, Whisper, Transformers, and pytube packages. Next, we'll import Whisper and the YouTube class from pytube:
import whisper
from pytube import YouTubeLooking at the Whisper model card, we see there several different model sizes we can use.
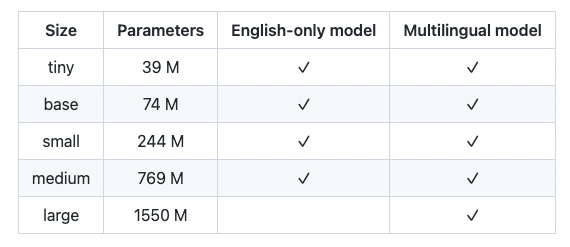
For this project, we'll just use the base model, which we load in like this:
model = whisper.load_model('base')Next, we need to instantiate a YouTube object and pass in the video URL in order to retrieve the meta data and stream info:
youtube_video_url = "https://www.youtube.com/watch?v=P7wUNMyK3Gs"
youtube_video = YouTube(youtube_video_url)With our pytube YouTube object, we can see the full video directory like so:
dir(youtube_video)
In order to get the transcription, we want to filter out the actual video and just get the audio stream:
streams = youtube_video.streams.filter(only_audio=True)
streams
Since we don't need to the highest quality audio for this project, we'll just use the first audio stream availabel
stream = streams.first()Now that we have the audio stream we'll be work with, let's download it to Colab as an MP4:
stream.download(filename='musk_interview.mp4')Now, in order to get the transcription using Whisper, all we need to do is call model.transcribe() like so:
output = model.transcribe("/content/musk_interview.mp4")
output
Stay up to date with AI
2. Prepare the transcript for GPT-3 fine-tuning
Now that we have the video transcription, we need to prepare it for GPT-3 fine tuning, which will enable use to compute the transcript embeddings and query the video using natural language.
For data preprocessing, I've broken the text up with the .split(), added the following columns: title, heading, content, tokens, and saved the file to CSV.
Next, we'll read the preprocessed CSV as follows:
df = pd.read_csv('/content/elon_interview.csv')
df = df.set_index(["title", "heading"])
print(f"{len(df)} rows in the data.")
df.sample(10)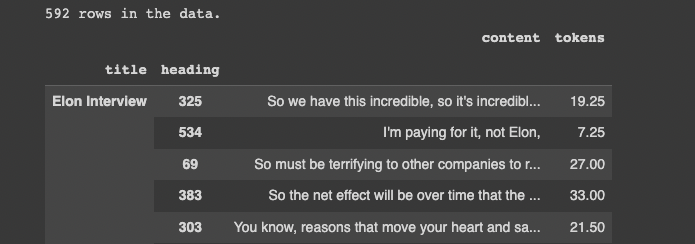
3. Compute the transcript & query embeddings
Next up, we need to write several functions that compute the embeddings of both the transcript and the user's query. As OpenAI highlights:
Embeddings are numerical representations of concepts converted to number sequences, which make it easy for computers to understand the relationships between those concepts.
To do so, we use the following functions from this OpenAI notebook:
get_embeddingget_doc_embeddingget_query_embeddingcompute_doc_embeddings
Below we can see what an example embedding looks like:
example_entry = list(context_embeddings.items())[0]
print(f"{example_entry[0]} : {example_entry[1][:5]}... ({len(example_entry[1])} entries)")
4. Retrieve similar transcript & query embeddings
Now that we have our transcript split into sections and encoded them into embeddings, next we need to retrieve similar transcript embeddings as the query embeddings.
In particular, we want our fine-tuned GPT-3 to provide answers to our queries based on relevant sections from the transcript.
We also don't want it to "hallucinate" (i.e. answer incorrectly), instead we want it to just answer based on the transcript provided and nothing else.
As OpenAI fine-tuning docs highlights:
Base GPT-3 models do a good job at answering questions when the answer is contained within the paragraph, however if the answer isn't contained, the base models tend to try their best to answer anyway, often leading to confabulated answers.
That being said, now we will use the following functions from the aforementioned OpenAI notebook:
vector_similarity: Calculate the similarity between vectorsorder_document_sections_by_query_similarity: Find query embeddings and compare it against all of the transcript embeddings to find the most relevant sections.
Here we can see we've retrieved relevant transcript sections for the query "What did Elon say about Twitter?":
order_document_sections_by_query_similarity("What did Elon say about Twitter?", context_embeddings)[:5]
5. Construct a prompt with relevant transcript sections
Next up, we need to construct a prompt that makes use of these relevant transcript sections.
To do so, we'll use the contruct_prompt function from the notebook:
prompt = construct_prompt(
"What did Elon say about Twitter?",
context_embeddings,
df
)
print("===\n", prompt)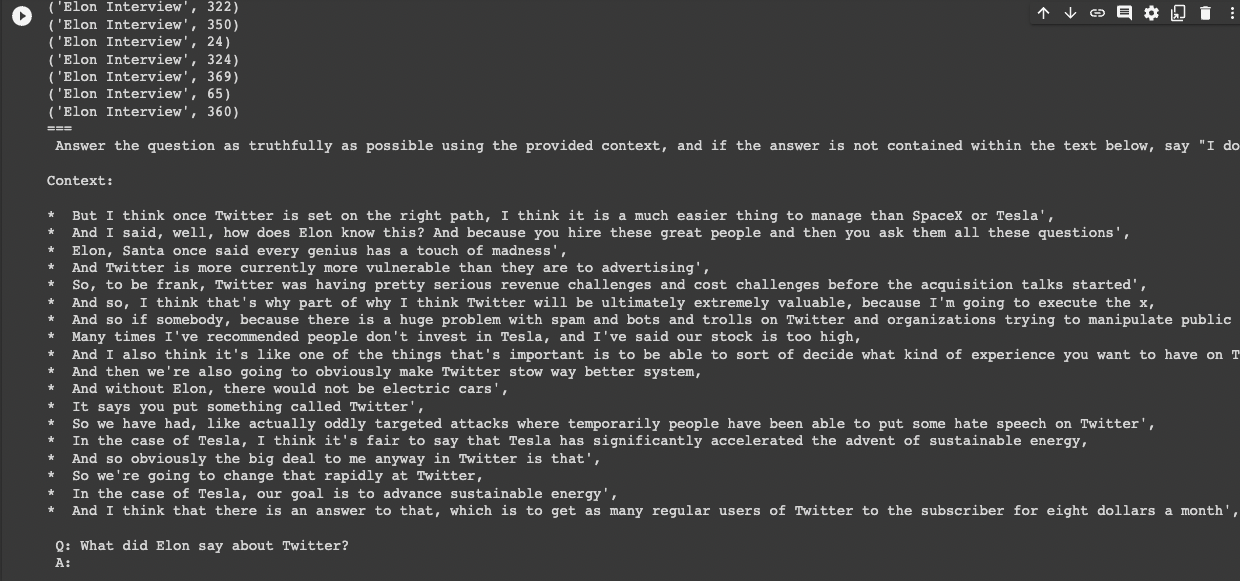
Above we can see we've found transcript sections that contain relevant information to our query and added it to our prompt...now we just need to actually answer the question.
6. Answer the query with relevant transcript context
Now that we have constructed a query with relevant transcript context, we just need to actually answer it with OpenAI's Completions API.
Since we want it to answer accurately based only on the transcript, we're going to set the temperature parameter to 0 as the docs suggest:
Higher temperatue values means the model will take more risks. Try 0.9 for more creative applications, and 0 (argmax sampling) for ones with a well-defined answer.
In order to answer the question with context from the transcript, we're going to use the answer_query_with_context function from the notebook:
answer_query_with_context("What did Elon say about Twitter?", df, context_embeddings)Elon said that Twitter was having serious revenue and cost challenges before the acquisition talks started, and that he was going to execute a plan to make Twitter a better system and to get more regular users to subscribe for $8 a month.
Nice! We now have a fine-tuned version of GPT-3 that can answer questions about the interview.
7. Summarizing the interview with prompt engineering
We now have everything we need to use natural language to summarize the interview.
Now we just need to do some prompt engineering to extract the most relevant topics of the interview, and then to summarize and provide quotes about those topics.
For this particular interview, I asked GPT-3 to summarize and provide quotes about the following topics:
- Tesla
- Autonomous driving
- Starship and the moon
- Becoming a multi-planetary species
The critical breakthrough needed to make life multiplanetary and for humanity to be a space-bearing civilization is a fully and rapidly reusable rocket, global rocket. - Elon Musk
You can find the full summary of the interview below:
 MLQ
MLQ
Summary: Summarizing YouTube Videos with OpenAI Whisper & GPT-3 Fine Tuning
In this article, we saw how we can combine OpenAI's Whisper and GPT-3 fine tuning to answer questions and summarize a YouTube video.
In particular, we used Whisper to transcribe an Elon Musk interview,
- Used Whisper to transcribe an Elon Musk interview
- Fine-tuned GPT-3 to answer questions accurately about the interview
- Used prompt engineering to summarize the interview
While there are certainly more steps we can take to automate this entire process even more, such as automated data preprocessing, this works well for an MVP of the idea.
If you want to learn more about GPT-3 fine tuning you can check out our other articles below:
- Fine-Tuning GPT-3: Using Embeddings for Semantic Search, Classification & Regression
- Fine-Tuning GPT-3: Building a Crypto Research Assistant
- Fine-Tuning GPT-3: Building an IPO Research Assistant
- Fine-Tuning GPT-3: Building an Earnings Call Assistant
- Fine Tuning GPT-3: Building a Custom Q&A Bot




