

In this guide, we're going to look at how to use the OpenAI Embeddings API and build a factual GPT-3 question-and-answering bot.
Check are the article below if you want to learn about GPT-3.5 turbo fine tuning:
 Peter Foy
Peter Foy
As you probably know by now, GPT-3 is pre-trained on basically the entire internet, which is great for general-purpose chatbots as we've seen with ChatGPT. That said, for domain-specific tasks that require factual answers, the base models of GPT-3 often fail...as the docs highlight:
Base GPT-3 models do a good job at answering questions when the answer is contained within the paragraph, however if the answer isn't contained, the base models tend to try their best to answer anyway, often leading to confabulated answers.
Instead o fine-tuning which involves updating the weights of the base model LLM, for a factual Q&A bot we can often achieve the results we want with the Embeddings API.
With the Embeddings API, we provide a separate document that contains relevant information, we then find sections of that document that are similar to the user's query, and create a dynamic prompt with this information to answer the question.
When given a prompt with just a few examples, it can often intuit what task you are trying to perform and generate a plausible completion.
You can learn more about the difference between embedding and fine-tuning in our guide GPT-3 Fine Tuning: Key Concepts & Use Cases.
In order to create a question-answering bot, at a high level we need to:
- Prepare and upload a training dataset
- Find the most similar document embeddings to the question embedding
- Add the most relevant document sections to the query prompt
- Answer the user's question based on additional context
To understand this process, let's go through the Question Answering Using Embeddings notebook provided by OpenAI.
Also, if you want to see how you can use the Embeddings & Completions API to build simple web apps using Streamlit, check out our video tutorials below:
- MLQ Academy: Create a Custom Q&A Bot with GPT-3 & Embeddings
- MLQ Academy: PDF to Q&A Assistant using Embeddings & GPT-3
- MLQ Academy: Build a YouTube Video Assistant Using Whisper & GPT-3
- MLQ Academy: Build a GPT-3 Enabled Earnings Call Assistant
- MLQ Academy: Building a GPT-3 Enabled App with Streamlit
Use Cases of the Embeddings API
As mentioned, there are many real-world use cases that require GPT-3 to respond accurately to a user's question.
A few examples of useful GPT-enabled Q&A bots include:
- Customer service chatbots that provide answers to commonly asked questions
- Code documentation bot that provides answers to developer questions
- Legal Q&A bot that provides accurate answers to legal questions
- Medical Q&A bot that answers patient questions
- Earnings call transcript AI that answers questions about key points discussed during the call
As Sam Altman highlights in this insightful talk, there will likely only be a few companies that have the budget to build and manage Large Language Models (LLMs) like GPT-3, but there will be many billion dollar+ "layer two" companies built in the next decade.
By "layer two", Sam is referring to companies built on top of fine-tuned base models that unlock efficiency and progress in domain-specific industries.
While he does say the "AI for everything" trend is a bit of a warning sign, there's no question that fine-tuning large language models and using Embeddings API as we'll discuss below (and the companies built around them) will be a massive business in the next decade.
Stay up to date with AI
Introduction: Building a Question Answering Bot using Embeddings
As the notebook highlights:
The GPT models have picked up a lot of general knowledge in training, but we often need to ingest and use a large library of more specific information.
In the example notebook, they've prepared a dataset of Wikipedia articles about the 2020 Summer Olympic games. You can check out this notebook for an example fo how to gather data for fine-tuning, although we'll save that for another article.
First, let's import the following packages, set our API key, and define the completions model we want to use. text-davinci-003 is the most recent and highest performing model at the time of writing, so we'll use that for this example:
import openai
import pandas as pd
import numpy as np
import pickle
from transformers import GPT2TokenizerFast
from typing import List
openai.api_key = "YOUR-API-KEY"
COMPLETIONS_MODEL = "text-davinci-003"Now, let's see why we need to use embeddings in the first place...we can see it isn't an expert on the 2020 Olympic Games out of the box:
prompt = "Who won the 2020 Summer Olympics men's high jump?"
openai.Completion.create(
prompt=prompt,
temperature=0,
max_tokens=300,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
model=COMPLETIONS_MODEL
)["choices"][0]["text"].strip(" \n")Marcelo Chierighini of Brazil won the gold medal in the men's high jump at the 2020 Summer Olympics.Marcelo Chierghini is indeed a Brazilian olympian, although he is a swimmer and came 8th in the 2020 Olympics...
This is what's referred to as the model "hallucinating" an answer instead of just saying "I don't know" as a good AI should.
Step 0: Prevent hallucination with prompt engineering
As a quick fix, we can address the hallucination problem with prompt engineering, or in other words, being more explicit in the instructions provided.
Below, we'll use the prompt "Answer the question as truthfully as possible, and if you're unsure of the answer, say "Sorry, I don't know" and then ask our Olympics question:
prompt = """Answer the question as truthfully as possible, and if you're unsure of the answer, say "Sorry, I don't know".
Q: Who won the 2020 Summer Olympics men's high jump?
A:"""
openai.Completion.create(
prompt=prompt,
temperature=0,
max_tokens=300,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
model=COMPLETIONS_MODEL
)["choices"][0]["text"].strip(" \n")Sorry, I don't know.Alright, now let's add some extra context to the prompt that gives the answer we're looking for. Note, if the amount of context is relatively short we can just include it in the prompt directly.
This often isn't practical as the context or dataset usually can't fit into the prompt, but here's an example anyways:
prompt = """Answer the question as truthfully as possible using the provided text, and if the answer is not contained within the text below, say "I don't know"
Context:
The men's high jump event at the 2020 Summer Olympics took place between 30 July and 1 August 2021 at the Olympic Stadium.
33 athletes from 24 nations competed; the total possible number depended on how many nations would use universality places
to enter athletes in addition to the 32 qualifying through mark or ranking (no universality places were used in 2021).
Italian athlete Gianmarco Tamberi along with Qatari athlete Mutaz Essa Barshim emerged as joint winners of the event following
a tie between both of them as they cleared 2.37m. Both Tamberi and Barshim agreed to share the gold medal in a rare instance
where the athletes of different nations had agreed to share the same medal in the history of Olympics.
Barshim in particular was heard to ask a competition official "Can we have two golds?" in response to being offered a
'jump off'. Maksim Nedasekau of Belarus took bronze. The medals were the first ever in the men's high jump for Italy and
Belarus, the first gold in the men's high jump for Italy and Qatar, and the third consecutive medal in the men's high jump
for Qatar (all by Barshim). Barshim became only the second man to earn three medals in high jump, joining Patrik Sjöberg
of Sweden (1984 to 1992).
Q: Who won the 2020 Summer Olympics men's high jump?
A:"""
openai.Completion.create(
prompt=prompt,
temperature=0,
max_tokens=300,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
model=COMPLETIONS_MODEL
)["choices"][0]["text"].strip(" \n")Gianmarco Tamberi and Mutaz Essa Barshim emerged as joint winners of the event.Success! Here we can see that with a little prompt engineering we can get the right answer, but as mentioned that isn't very practical.
What do we do when we have a large dataset of information to parse through?
This is where Embedding API comes into play.
Next, we'll walk through how to provide contextual information by using document embeddings and retrieval.
Here's how this works at a high level:
- First, it retrieves the information relevant to the user's query
- Next, it uses the Completions API to answer accurately
More specifically, the steps we need to take include:
- Preprocess the contextual information by splitting it into smaller pieces and creating an embedding vector for each subset
- After a query is received, embed the query in the same vector space as the smaller subsets and find the most relevant context embeddings to the user query
- Prepend the most relevant context embeddings to the user's query prompt
- Submit the question along with the most relevant context to GPT-3 and receive an answer that uses said contextual information
Let's get started.
Step 1: Preprocess the document
As mentioned, the first step is to preprocess a document that contains the contextual information for our use case.
In order to prepare your data, the notebook suggests the following:
Sections should be large enough to contain enough information to answer a question; but small enough to fit one or several into the GPT-3 prompt. We find that approximately a paragraph of text is usually a good length, but you should experiment for your particular use case.
OpenAI has their processed dataset hosted, so let's use that for now:
df = pd.read_csv('https://cdn.openai.com/API/examples/data/olympics_sections_text.csv')
df = df.set_index(["title", "heading"])
print(f"{len(df)} rows in the data.")
df.sample(5)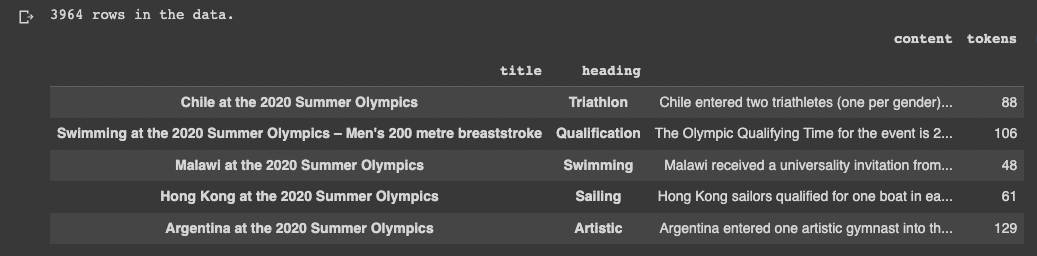
Next, we're going to set the model for the task of document and query vector embedding. In this example, they used the Curie model:
MODEL_NAME = "curie"
DOC_EMBEDDINGS_MODEL = f"text-search-{MODEL_NAME}-doc-001"
QUERY_EMBEDDINGS_MODEL = f"text-search-{MODEL_NAME}-query-001"Next, we'll create functions to get the embedding, get the document and query embedding, and compute the embedding:
def get_embedding(text: str, model: str) -> List[float]:
result = openai.Embedding.create(
model=model,
input=text)
return result["data"][0]["embedding"]
def get_doc_embedding(text: str) -> List[float]:
return get_embedding(text, DOC_EMBEDDINGS_MODEL)
def get_query_embedding(text: str) -> List[float]:
return get_embedding(text, QUERY_EMBEDDINGS_MODEL)
def compute_doc_embeddings(df: pd.DataFrame) -> Dict[Tuple[str, str], List[float]]:
"""
Create an embedding for each row in the dataframe using the OpenAI Embeddings API.
Return a dictionary that maps between each embedding vector and the index of the row that it corresponds to.
"""
return {
idx: get_doc_embedding(r.content.replace("\n", " ")) for idx, r in df.iterrows()
}Then we'll create a function called load_embeddings that reads the document embeddings and their keys from a CSV.
def load_embeddings(fname: str) -> Dict[Tuple[str, str], List[float]]:
"""
Read the document embeddings and their keys from a CSV.
fname is the path to a CSV with exactly these named columns:
"title", "heading", "0", "1", ... up to the length of the embedding vectors.
"""
df = pd.read_csv(fname, header=0)
max_dim = max([int(c) for c in df.columns if c != "title" and c != "heading"])
return {
(r.title, r.heading): [r[str(i)] for i in range(max_dim + 1)] for _, r in df.iterrows()
}Next, we're going to load the document embeddings. Again, OpenAI has provided their embeddings, although there is commented out code below if you want to recalculate these embeddings from scratch:
document_embeddings = load_embeddings("https://cdn.openai.com/API/examples/data/olympics_sections_document_embeddings.csv")
# ===== OR, uncomment the below line to recaculate the embeddings from scratch. ========
# context_embeddings = compute_doc_embeddings(df)Below we can check out an example embedding:
# An example embedding:
example_entry = list(document_embeddings.items())[0]
print(f"{example_entry[0]} : {example_entry[1][:5]}... ({len(example_entry[1])} entries)")
We've now split our document into sections and encoded them by creating embedding vectors for each subset of the data.
The next step is to use these embeddings to answer the user's question.
Step 2: Find similar document embeddings to the question embedding
In order to actually answer a user's query, we first compute the query embedding of the question and then use it to find the most similar document sections.
For this smaller example, the embeddings are stored locally but for larger datasets, we can use a vector search engine like Pinecone or Weaviate.
First, let's calculate the similarity between vectors:
def vector_similarity(x: List[float], y: List[float]) -> float:
"""
We could use cosine similarity or dot product to calculate the similarity between vectors.
In practice, we have found it makes little difference.
"""
return np.dot(np.array(x), np.array(y))Next, we want find to find the query embedding and compare it to the document embeddings to find the most relevant sections:
def order_document_sections_by_query_similarity(query: str, contexts: Dict[Tuple[str, str], np.array]) -> List[Tuple[float, Tuple[str, str]]]:
"""
Find the query embedding for the supplied query, and compare it against all of the pre-calculated document embeddings
to find the most relevant sections.
Return the list of document sections, sorted by relevance in descending order.
"""
query_embedding = get_query_embedding(query)
document_similarities = sorted([
(vector_similarity(query_embedding, doc_embedding), doc_index) for doc_index, doc_embedding in contexts.items()
], reverse=True)
return document_similaritiesBelow we can use this function to find the most relevant sections related to the supplied query:
order_document_sections_by_query_similarity("Who won the men's high jump?", document_embeddings)[:5]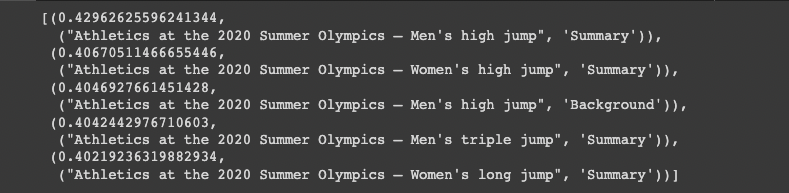
3. Add relevant document sections to the query prompt
The next step is to add this relevant context from the document sections to a prompt by prepending them to the supplied query. As the notebook suggests, it's "helpful to use a query separator to help the model distinguish between separate pieces of text":
MAX_SECTION_LEN = 500
SEPARATOR = "\n* "
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")
separator_len = len(tokenizer.tokenize(SEPARATOR))
f"Context separator contains {separator_len} tokens"
Now we'll create a function to construct the new prompt with the most relevant document sections:
def construct_prompt(question: str, context_embeddings: dict, df: pd.DataFrame) -> str:
"""
Fetch relevant
"""
most_relevant_document_sections = order_document_sections_by_query_similarity(question, context_embeddings)
chosen_sections = []
chosen_sections_len = 0
chosen_sections_indexes = []
for _, section_index in most_relevant_document_sections:
# Add contexts until we run out of space.
document_section = df.loc[section_index]
chosen_sections_len += document_section.tokens + separator_len
if chosen_sections_len > MAX_SECTION_LEN:
break
chosen_sections.append(SEPARATOR + document_section.content.replace("\n", " "))
chosen_sections_indexes.append(str(section_index))
# Useful diagnostic information
print(f"Selected {len(chosen_sections)} document sections:")
print("\n".join(chosen_sections_indexes))
header = """Answer the question as truthfully as possible using the provided context, and if the answer is not contained within the text below, say "I don't know."\n\nContext:\n"""
return header + "".join(chosen_sections) + "\n\n Q: " + question + "\n A:"Now let's supply the prompt "Who won the 2020 Summer Olympics men's high jump?" and use our prompt_construct function:
prompt = construct_prompt(
"Who won the 2020 Summer Olympics men's high jump?",
document_embeddings,
df
)
print("===\n", prompt)
We now have the document sections that are most relevant to the question, the last step is to put it all together and actually answer the question.
4. Anwer the user's question based on context
In order to answer the question, we now need to use the Completions API. As highlighted below, we use a temparature of 0 in order to get the most predictable and factual answer (i.e. avoid hallucination):
COMPLETIONS_API_PARAMS = {
# We use temperature of 0.0 because it gives the most predictable, factual answer.
"temperature": 0.0,
"max_tokens": 300,
"model": COMPLETIONS_MODEL,
}Let's create a function to answer the query with the retrieved document context:
def answer_query_with_context(
query: str,
df: pd.DataFrame,
document_embeddings: Dict[Tuple[str, str], np.array],
show_prompt: bool = False
) -> str:
prompt = construct_prompt(
query,
document_embeddings,
df
)
if show_prompt:
print(prompt)
response = openai.Completion.create(
prompt=prompt,
**COMPLETIONS_API_PARAMS
)
return response["choices"][0]["text"].strip(" \n")Finally, let's use this function to answer our initial question:
answer_query_with_context("Who won the 2020 Summer Olympics men's high jump?", df, document_embeddings)
Success!
By combining the Embeddings and Completions API we were able to create a factual question-answering model that can answer questions based on a database of additional information GPT-3 didn't know before.
Let's also check if it responds "I don't know" to a query outside the database—here "Who won the 2023 Summer Olympics men's high jump?"

Looks good!
Summary: Using Embeddings to create a GPT-3 enabled Q&A bot
In this article, we saw how we can combine the Embeddings and Completions API to create a GPT-3 enabled bot that can answer questions based on an additional body of knowledge.
Specifically, we used the Embeddings API to retrieve relevant documents, add that context to the query, and answer factually or say "I don't know".
Although this isn't technically "fine-tuning", for many use cases that involve large text documents, in my experience using the Embeddings API and creating dynamic prompts with relevant information achieves superior results to traditional fine-tuning.
As discussed, the use cases of this are quite limitless, a few obvious examples of applications that could be built on top of this include:
- Legal Q&A bot based on additional knowledge
- Medical Q&A bot for specific domains
- Coding assistants that are fine-tuned on company documentation
- Customer service bots that are fine-tuned on a knowledge base
In quantitative finance, a few more examples of how GPT-3 could be fine-tuned include:
- Earnings call transcripts: Provide a summary and be able to ask questions about the call
- IPOs: Provide a summary of the prospectus and be able to answer questions
In this guide, we just went through the notebook and dataset OpenAI provided, so in the next article, we're going to test out Embeddings on our own dataset.
Given that earnings call transcripts are easily accessible and well-suited for language models, that is what we will work with. The goal will be to provide a summary of the call and then be able to answer analyst questions based on what was discussed.
Further Resources
- OpenAI Cookbook: Question Answering using Embeddings
- MLQ Academy: Create a Custom Q&A Bot with GPT-3 & Embeddings
- MLQ Academy: PDF to Q&A Assistant using Embeddings & GPT-3
- MLQ Academy: Build a YouTube Video Assistant Using Whisper & GPT-3
- MLQ Academy: Build a GPT-3 Enabled Earnings Call Assistant
- MLQ Academy: Building a GPT-3 Enabled App with Streamlit




