

In our previous guide on Getting Started with LangChain, we discussed how the library is filling in many of the missing pieces when it comes to building more advanced large language model (LLM) applications.
One of the many interesting features they offer is a number of Document Loader modules that make it much easier to work with external data:
Combining language models with your own text data is a powerful way to differentiate them. The first step in doing this is to load the data into “documents” - a fancy way of say some pieces of text.
In this guide, we'll look at how we can use LangChain and the Unstructured python package to transform various types of type files into text. Specifically, we can use this package to transform PDFs, PowerPoints, images, and HTML into text.
We can then use OpenAI's embeddings and be able to ask questions about our document. The steps we need to take to do this include
- Installs and Imports
- Uploading unstructured documents
- Splitting documents into smaller chunks of text
- Retrieve document embeddings with OpenAI
- Including sources in our responses
 Peter Foy
Peter Foy
1. Installs and Imports
To get started, we first need to pip install the following packages and system dependencies:
- Libraries: LangChain, OpenAI, Unstructured, Python-Magic, ChromaDB, Detectron2, Layoutparser, and Pillow.
- System dependencies: libmagic-dev, poppler-utils, and tesseract-ocr.
Next, let's import the following libraries and LangChain modules:
- OpenAIEmbeddings and Chroma classes for creating embeddings and vector stores, respectively.
- We also import the OpenAI and VectorDBQA classes for performing natural language processing tasks.
- We then import some document loaders and text splitters from the langchain library.
- We need to import the magic module for detecting file types and the NLTK module for tokenizing text.
- Finally, let's set the OpenAI API key as an environment variable.
import langchain
import openai
import os
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain import OpenAI, VectorDBQA
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import UnstructuredFileLoader
import magic
import nltk
nltk.download('punkt')
os.environ["OPENAI_API_KEY"] = "YOUR-API-KEY"
2. Uploading unstructured documents
Next, we'll upload our text file to Google Colab:
from google.colab import files
uploaded = files.upload()In this case, I've uploaded this computer vision paper as a PDF and we can load it in using the UnstructuredFileLoader from LangChain:
- Here we set the file path and mode as "elements", which loads the file as a list of elements, which are basically small chunks of text.
- The
loaderis then used to load the document and store it in a variable calleddocuments
loader = UnstructuredFileLoader('path-to-document', mode="elements")
documents = loader.load()
print (f'You have {len(documents)} document(s) in your data')
documents[:5]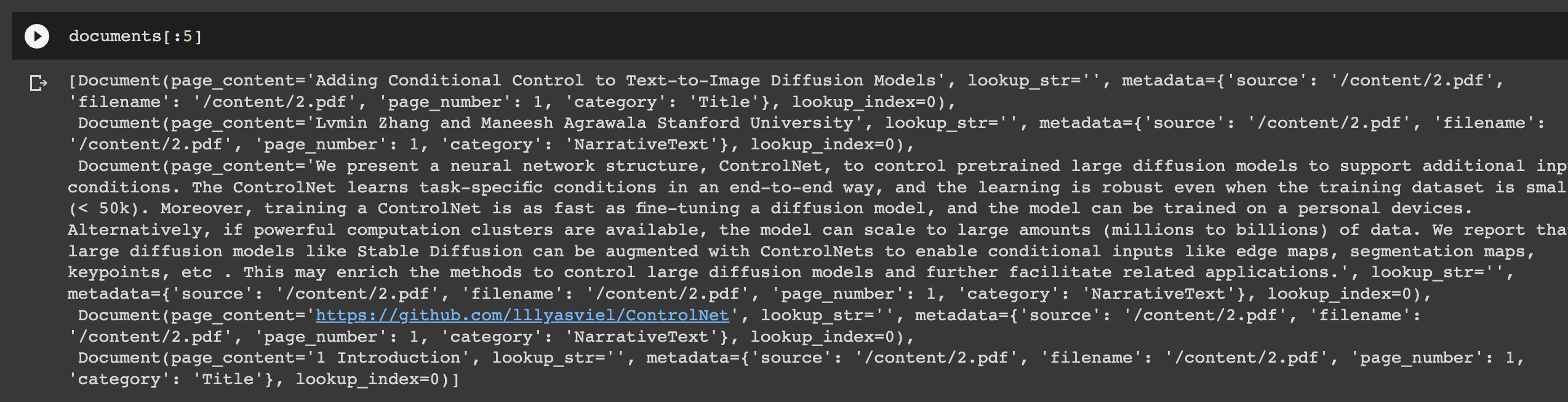
3. Splitting documents into smaller chunks of text
Now that we've loaded our document, we need to split the text up so that we don't run into token limits when we retrieve relevant document information.
To do so, we can use the CharacterTextSplitter from LangChain and in this case we'll split the documents in chunk sizes of 1000 characters, with no overlap between the chunks.
The text_splitter is used to split the documents and store the resulting chunks in a variable called "texts":
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
texts[:10]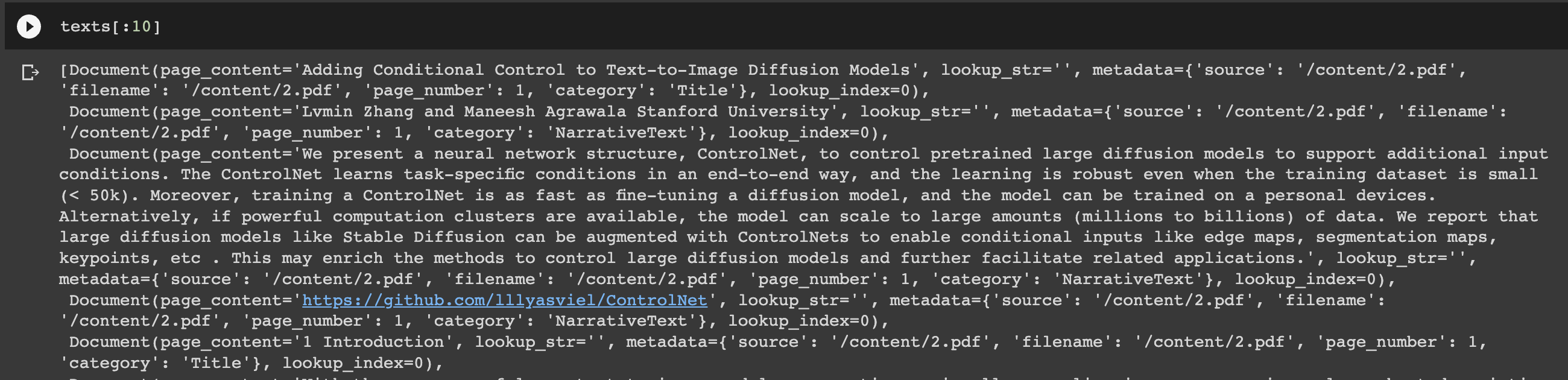
4. Retrieve document embeddings with OpenAI
Now that we've split our documents into smaller subsections, we need to calculate the embeddings of these sections using OpenAI. As OpenAI writes:
OpenAI’s text embeddings measure the relatedness of text strings. An embedding is a vector (list) of floating point numbers. The distance between two vectors measures their relatedness. Small distances suggest high relatedness and large distances suggest low relatedness.
Here's a breakdown of the code below:
- We first generates embeddings for the text using OpenAI embeddings. We create an
OpenAIEmbeddingsobject and sets the OpenAI API key as a parameter. - The
embeddingsobject is used to generate embeddings for the text chunks. - Next, the code creates a
Chromaobject using the texts and embeddings, which is a vector store that allows for efficient searching and comparison of embeddings. The Chroma object is stored in a variable calleddocsearch. - We then create a
VectorDBQAobject from the langchain library to perform question-answering on the text data. - We sets the OpenAI language model as the
llmparameter and sets thechain_typeas "stuff". It also sets the Chroma object as the vectorstore parameter. - Finally, we run a sample query for the paper using the
run()method of the VectorDBQA object.
embeddings = OpenAIEmbeddings(openai_api_key=os.environ['OPENAI_API_KEY'])
docsearch = Chroma.from_documents(texts, embeddings)
qa = VectorDBQA.from_chain_type(llm=OpenAI(), chain_type="stuff", vectorstore=docsearch)
query = "Write an introduction Adding Conditional Control to Text-to-Image"
qa.run(query)
Simple as that! In just a few lines of code we're able to upload an unstructured PDF document, convert it to text and calculate the embeddings, and then ask questions about the document.
5. Including sources in the responses
When it comes to working with a large amount of unstructured data, whether for research or other purposes, we often want to be able to include the sources where the LLM is retrieving its information.
We can modify the code to return_source_documents=True and then view the sources with with result['source_documents'] as follows:
qa = VectorDBQA.from_chain_type(llm=OpenAI(), chain_type="stuff", vectorstore=docsearch, return_source_documents=True)
query = "Write a summary of Adding Conditional Control to Text-to-Image"
result = qa({'query': query})
result['result']
result['source_documents']
Stay up to date with AI
Summary: Building an AI document assistant
As I continue to work on building an end-t0-end GPT-3 enabled research assistant, the ability to be able to load large quantities of unstructured data is a key building block for this project.
I've written several articles on working with GPT-3 and external documents, although you can see how much less code we need to write with LangChain to accomplish the same task. Given that this also works with any file type, you can start to see how powerful it is.
Now that we've got this step ready to go, in the next article we'll check out how we can retrieve document embeddings for multiple documents and also store these embeddings in Pinecone, which is a:
...vector database makes it easy to build high-performance vector search applications.
Until then, you can check out our previous articles on GPT-3 here.




