

In our previous article on creating a custom Q&A bot with the Embeddings API, we saw how we can build a factual question-and-answering bot based on an additional body of knowledge.
There are a number of reasons you may want to use the Embeddings API, but one of the main reasons for real-world use is that if you're looking for factual answers, in which case the base GPT-3 model often fails as highlighted in the docs:
Base GPT-3 models do a good job at answering questions when the answer is contained within the paragraph, however if the answer isn't contained, the base models tend to try their best to answer anyway, often leading to confabulated answers.
Another key reason to fine-tune or use embeddings is that the base GPT-3 model is only trained on data until 2021, so training it on a separate body of knowledge can be extremely valuable for certain text-heavy industries such as finance, legal, healthcare, and so on.
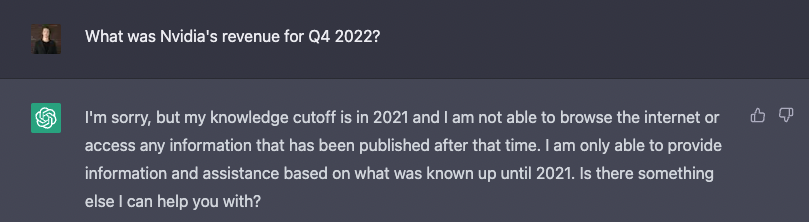
For example, if we ask "What was Nvidia's revenue for Q4 2022?", ChatGPT unable to answer:
The possibilities of fine-tuning GPT-3 or using embeddings for domain-specific tasks are quite endless and we've undoubtedly entered the "Copilot for X" phase of the AI hype cycle.
In the previous article, we used the Embeddings API to train GPT-3 on a dataset provided by OpenAI for the 2020 summer Olympic games, so in this article, we're going to fine-tune it on something a bit more useful: earnings call transcripts.
There are many reasons why using GPT-3 for earnings call transcripts is useful, but the main one is they're long and often boring to read, so it would be nice if we can just extract key information and ask questions about it conversationally.
We've now integrated an updated version of our Earnings Call Assistant in the MLQ app, which you can sign up for here.
EarningsGPT: a GPT-3 Enabled Earnings Call Transcript Assistant
The idea behind this project is to build an AI assistant that can provide a summary of the earnings by answering questions factually based on the transcript.
There has been a lot of work done on sentiment analysis of earnings calls, although I've yet to see anyone provide accurate and timely summaries of earnings calls, or anything you can query conversationally.
Of course, we will need the AI to only answer the question if relevant context is provided in the earnings call, and it can't "hallucinate"—which is the term used to describe when GPT-3 starts answering questions convincingly, albeit totally inaccurately...aka confident BS.
In the previous article, we saw how to avoid hallucinations and fine-tune GPT to answer factually based on an additional body of knowledge. The steps I need to take to build this earnings call assistant include:
- Step 1: Get the earnings call transcript
- Step 2: Prepare the data for GPT-3 fine-tuning
- Step 3: Compute the document & query embeddings
- Step 4: Find the most similar document embedding to the question embedding
- Step 5: Add the most relevant document sections to the query prompt
- Step 6: Answer the user's question based on context
- Step 7: Building a GPT-3 enabled earnings call summary
Also, if you want to see how you can use the Embeddings & Completions API to build simple web apps using Streamlit, check out our video tutorials below:
- MLQ Academy: Create a Custom Q&A Bot with GPT-3 & Embeddings
- MLQ Academy: PDF to Q&A Assistant using Embeddings & GPT-3
- MLQ Academy: Build a YouTube Video Assistant Using Whisper & GPT-3
- MLQ Academy: Build a GPT-3 Enabled Earnings Call Assistant
- MLQ Academy: Building a GPT-3 Enabled App with Streamlit
Stay up to date with AI
Step 1: Get the earnings call transcript
The first step is to get the earnings call transcript data, which is easy as they are a number of APIs or we could just copy the text from several free sources.
For this project, we've used this Earnings Call Transcript API and added it to the MLQ app. I'll be using Nvidia's Q4 2022 earnings call transcript, which you can find online here.
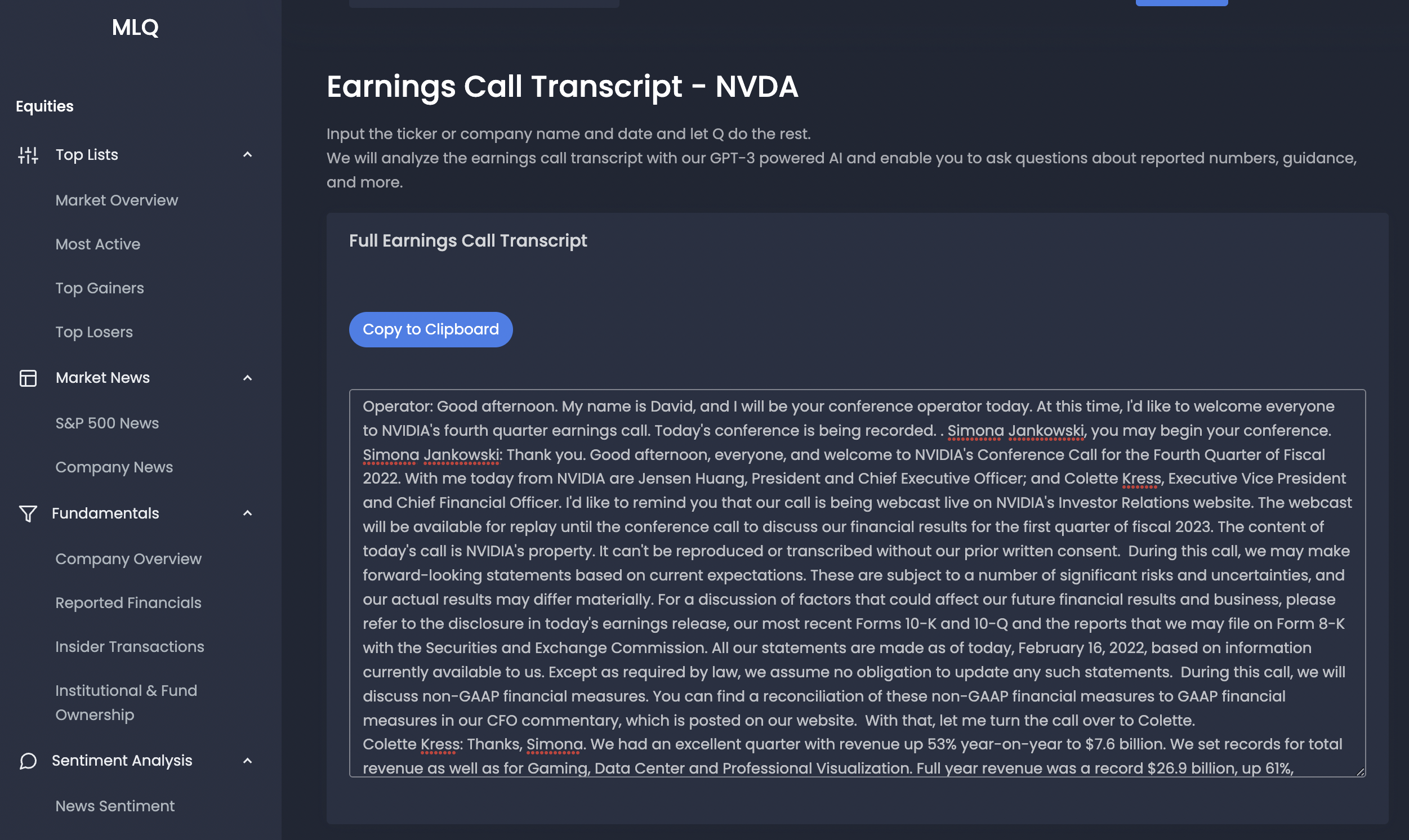
Step 2: Prepare the data for GPT-3 fine-tuning
Next, we need to preprocess the data by splitting the earnings call into sections that can be searched and retrieved separately.
As the OpenAI notebook suggests:
Sections should be large enough to contain enough information to answer a question; but small enough to fit one or several into the GPT-3 prompt. We find that approximately a paragraph of text is usually a good length, but you should experiment for your particular use case.
These may still be a bit long, but they should be okay to test. Also, another step I could take in the future is automatically tagging the "heading" section with data labels relevant to the text, but for the MVP, I've just numbered the sections.

Step 3: Compute the document & query embeddings
The next step is to upload this preprocessed data and create an embedding vector for each section. As the notebook highlights:
An embedding is a vector of numbers that helps us understand how semantically similar or different the texts are. The closer two embeddings are to each other, the more similar are their contents
We won't cover embeddings in detail in this article, although you can learn more about them in the OpenAI documentation here.
In addition to the document embeddings, we also need a function to compute the query embeddings so we can retrieve the most relevant sections related to the question.
In order to compute the vectors for each section, we use the Curie model and make use of the following functions from our previous article:
get_embeddingget_doc_embeddingget_query_embeddingcompute_doc_embeddings
In terms of computing the document embeddings, what we're doing is creating an embedding for each row in the data frame using the OpenAI Embeddings API.
This then returns a dictionary that maps between each embedding vector and the index of the row that it corresponds to. We then need to read these document embeddings and their keys from a CSV. Below is an example embedding:

Ok, we now have our earnings call transcript split into sections and encoded each of them with embedding vectors. Next, we will use these embeddings to answer the user's question.
Step 4: Find the most similar document embedding to the question embedding
We now have both document and query embeddings, so in order to actually answer a user's question, we need to find the most similar document sections related to the query.
To do this, we'll use the following functions from the notebook:
vector_similarity- calculate the similarity between vectorsorder_document_sections_by_query_similarity- Find the query embedding for the supplied query, and compare it against all of the pre-calculated document embeddings to find the most relevant sections. Return the list of document sections, sorted by relevance in descending order.
Let's look at the embeddings for a simple question: What quarter is the call about?
order_document_sections_by_query_similarity("What quarter is this earnings call about?", context_embeddings)[:5]
Here we can see these are relevant document sections that are similar to the query (i.e. contain the answer) as we would expect, moving on.
Step 5: Add the most relevant document sections to the query prompt
Now that we've found the document sections of the earnings call transcript that contain relevant context, we need to construct a prompt that contains this information.
To do this, we'll use the construct_prompt function from the notebook:
prompt = construct_prompt(
"what was the revenue for Q4 2022",
context_embeddings,
df
)
print("===\n", prompt)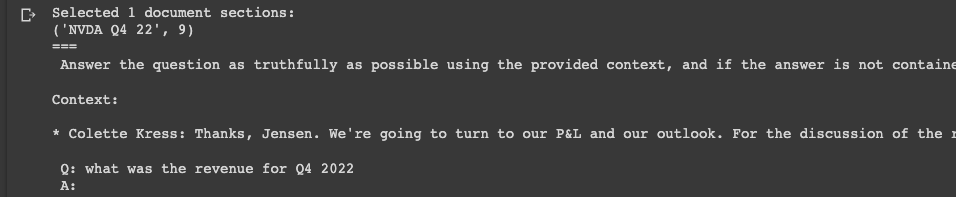
Here we can see it's found a relevant document section that contains context to the question "What was the revenue for Q4 2022?"...Colette Kress is the CFO so that's looking good so far.
As a next step, we need to actually answer the question based on this context.
Step 6: Answer the user's question based on context
To recap, we've now retrieved the relevant context to the user's question and constructed a prompt. We now need to use the Completions API to answer the question.
Again we need to use a temperature of 0 in order to ensure the bot answers factually and doesn't hallucinate.
We'll then use the answer_query_with_context function from the article:
answer_query_with_context("What was the revenue for the quarter", df, context_embeddings)
Success! If we check the full transcript we see that...
We had an excellent quarter with revenue up 53% year on year to $7.6 billion.
Interestingly, if I phrase the question as "What was the revenue for Q4?" it responds "I don't know"...so I clearly need to solve that and be selective with my prompts for now.
I think I just need to be a bit broader with keywords and more explicit in my response requirements, for example by saying something like "Provide details on anytime revenue was mentioned on the call. Write 3-5 sentences on this and answer like an analyst."... I get this answer:
Colette Kress mentioned that revenue for the first quarter of fiscal 2023 is expected to be $8.1 billion, plus or minus 2%. She also mentioned that sequential growth is expected to be driven primarily by Data Center and Gaming. Additionally, Colette Kress mentioned that GAAP and non-GAAP gross margins are expected to be 65.2% and 67%, respectively, plus or minus 50 basis points. Finally, she mentioned that capital expenditures are expected to be approximately $350 million to 400 million.
Much better, although now I'm not getting any mention of the $7.6 billion revenue for the quarter...I'll dig into this more later, but for now let's keep building.
Step 7: Building a GPT-3 Enabled Earnings Call Summary
As I mentioned, I still need to be cautious when constructing prompts to get my desired answer. With that in mind, instead of making an open-ended chatbot right away, let's see if I can just provide a set of 10 questions and get an earnings call summary.
First off, let's try prompts using broad, generic analyst questions. To do so, I've copied a list of questions from this article on the best questions to ask during an earnings call:
- What are some of the current and looming threats to the business?
- What is the debt level or debt ratio of the company right now?
- How do you feel about the upcoming product launches or new products?
- How are you managing or investing in your human capital?
- How do you track the trends in your industry?
- Are there major slowdowns in the production of goods?
- How will you maintain or surpass this performance in the next few quarters?
- What will your market look like in five years as a result of using your product or service?
- How are you going to address the risks that will affect the long-term growth of the company?
- How is the performance this quarter going to affect the long-term goals of the company?
Note: I purposely haven't read the full transcript yet because I wanted to see how it would do with general questions...
Nice! 7 out of 10 questions were answered...that's not bad for generic questions without reading the transcript.
Here's the answer to the question "What are some of the current and looming threats to the business?"
Currently, the main threat to the business is the supply constraints across some of the businesses, particularly in the Data Center business. This is something that the company is working to improve every day, and they expect to see improvement each quarter as they enter into fiscal year '23. Additionally, the company is working to package up software to be able to sell it separately, which could create a new business model and new partners to help sell it. This could be a driver for the company in the long term, but it is still uncertain how successful this will be. Finally, the company is also working to create new high-value platforms in the Data Center business, which could help with gross margins.
Quite impressive GPT-3. Ok let's check the transcript for the questions that weren't answered.
It looks like there was no mention of "human capital", "production of goods", or the "market in 5 yeays" on the call, so it's a good thing that the GPT-3 responded, "I don't know".
As a next step, I actually read the transcript and pulled out questions that I knew were answered on the call:
Here are the 10 new prompts:
- Revenue: Provide key information about revenue for the quarter
- Profitability: Provide key information about profits and losses (P&L) for the quarter
- Industry Trends: Provide key information about industry trends for the quarter
- Gaming: Provide key information about gaming discussed on the call
- GPUs: Provide key information about GPUs discussed on the call
- AI: Provide key information about AI discussed on the call
- Data centers: Provide key information about data centers discussed on the call
- M&A: Provide any information about mergers and acquisitions (M&A) discussed on the call.
- Guidance: Provide key information about guidance discussed on the call
- Data labeling: Provide a list of data labels related to important and recurring topics discussed on the call
Looks good! 9/10 questions answered. Here's what was said about AI on the call:
NVIDIA has been working to broaden the reach and ease the adoption of NVIDIA AI into vertical industries. They have released version 1.1 of their NVIDIA AI Enterprise software, allowing enterprises to accelerate annual workloads on VMware, on mainstream IT infrastructure. They have also expanded the number of system integrators qualified for NVIDIA AI Enterprise. Forrester Research has recognized NVIDIA in the top category of leaders in their evaluation of Enterprise AI infrastructure providers. Deloitte, a leading global consulting firm, has built its center for AI computing on NVIDIA DGX Superpod. At CES, NVIDIA extended their collaboration to AV development, leveraging their own robust AI infrastructure and Deloitte's team of 5,500 system integration developers and 2,000 data scientists to architect solutions for intelligent transportation.
The one that wasn't answered was related to M&A, although there was a discussion of the Arm acquisition on the call. To solve this I was more explicit in my prompt and asked it to talk about the acquisition of Arm...again still need to be selective with my prompts:
NVIDIA attempted to acquire Arm in September 2020, believing that it would accelerate Arm's focus on high-performance CPUs and help Arm expand into new markets. However, the transaction spurred questions from regulators worldwide and NVIDIA was unable to give regulators the comfort they needed to approve the deal. NVIDIA's work in accelerated computing and overall strategy will continue as before, and they are on track to launch their Arm-based CPU targeting giant AI and HPC workloads in the first half of next year. They also have a 20-year architectural license to Arm's IP, allowing them the full breadth and flexibility of options across technologies and markets.
I will still need to work on this as a user won't always ask questions so precisely, but this is a good start!
You can find the full EarningsGPT call summary of Nvidia Q 2022 results below:
 Peter Foy
Peter Foy
Summary: Building a GPT-3 Enabled Earnings Call Transcript Assistant
As we've discussed, in this article I fine-tuned GPT-3 to answer questions about Nvidia's Q4 2022 earnings call.
The steps we took to build this include:
- Step 1: Get the earnings call transcript
- Step 2: Prepare the data for GPT-3 fine-tuning
- Step 3: Compute the document & query embeddings
- Step 4: Find the most similar document embedding to the question embedding
- Step 5: Answer the user's question based on context
- Step 6: Building a GPT-3 Enabled Earnings Call Summary
After some more selective word choice in my prompts, the AI assistant was able to answer all questions accurately.
Of course, this is only an MVP a few next steps I can take include:
- Build an end-to-end data preparation pipeline: Right now I'm doing the data preprocessing myself but I can definitely write a script to automate this.
- Use GPT-3 for any asset: Right now with the manual data prep stage I can't open this up to every stock just yet, so that will be step 2.
- Add chat: Enable users to conversationally query GPT-3, ask new/follow up questions, ask it to write reports, and so on.
So far this has been a very fun project, and I may consider opening EarningsGPT up to more people. If you'd like to use GPT-3 in your own equity research and portfolio management process, you can contact us here and I'll be happy to discuss your use case.
Lastly, the exciting part is that earnings transcripts are by no means the only application of GPT-3 for finance, literally any financial document could be used for fine-tuning.
A few other examples that come to mind of where this could be valuable include:
- IPO prospectuses: Get a summary of IPO prospectuses upcoming that week
- M&A filings: Get a summary and ask questions about M&A activity in an industry
- Crypto whitepapers: Get a summary and ask questions about crypto assets
The list goes on...stay tuned, we may test out a few of these shortly.




