

In our previous articles on GPT-3, we saw how to build an earnings call transcript assistant and how to build a custom Q&A bot. Specifically, we used the Embeddings API and GPT-3 to answer factual questions from the earnings call and provide a detailed earnings call summary.
If you've tried ChatGPT at all, you know the reason that fine-tuning GPT-3 or using Embeddings is so important is that despite its incredible language generation capabilities, the base model can often be inaccurate when it comes to factual information.
Also, despite not knowing the answer, ChatGPT will respond anyways when it doesn't know the answer...in other words, it's a confident BS'er.
As the OpenAI docs highlight:
Base GPT-3 models do a good job at answering questions when the answer is contained within the paragraph, however if the answer isn't contained, the base models tend to try their best to answer anyway, often leading to confabulated answers.
Lastly, in addition to confabulated answers, GPT-3 is only trained on data until 2021 and doesn't have internet browsing access, which makes real-world use cases that require accurate nearly impossible...that's where fine-tuning comes in.
By using the Embeddings API with GPT-3, we can train it on an additional body of knowledge and tell it to only answer factually if the answer is actually available.
Ok, now we know why we need to augment GPT-3, let's look at another real-world use case in finance: building an IPO research assistant.
Also, if you want to see how you can use the Embeddings & Completions API to build simple web apps using Streamlit, check out our video tutorials below:
- MLQ Academy: Create a Custom Q&A Bot with GPT-3 & Embeddings
- MLQ Academy: PDF to Q&A Assistant using Embeddings & GPT-3
- MLQ Academy: Build a YouTube Video Assistant Using Whisper & GPT-3
- MLQ Academy: Build a GPT-3 Enabled Earnings Call Assistant
- MLQ Academy: Building a GPT-3 Enabled App with Streamlit
Overview: Building a GPT-3 Enabled IPO Research Assistant
There are a few reasons I chose IPOs for my next use case of fine-tuning GPT, namely:
- IPO prospectuses are long boring legal documents: it would useful to have an AI research assistant that can summarize and answer questions about the offering
- Recent IPOs won't be available with the GPT-3 base model: Since I'm looking at IPOs after 2021, all of this information won't be contained in the GPT-3 base model
- Answering factually is valuable in this case: Given that we know GPT-3 is a confident BS'er out-of-the-box and that we're dealing with legal documents, it's valuable to fine-tune it to only answer factually when the information is available, otherwise we want it to say "I don't know"
For example, if we ask ChatGPT about the Mobileye IPO it says:
On March 13, 2021, Mobileye went public on the New York Stock Exchange (NYSE) at a reference price of $25 per share. The stock opened for trading at a price of $60 per share, valuing the company at over $10 billion. The IPO was a huge success, with the stock price soaring as high as $64.70 per share on its first day of trading.

Unfortunately, none of that is true. The reference price was $25 for the first time Mobileye went public in 2012...so nice try GPT-3.
Ok now that we have an overview of the project, the steps we need to take to fine-tune GPT-3 will be the same as our custom Q&A bot, just with a different dataset. In particular, we need to:
- Step 1: Get the data (IPO prospectus in this case)
- Step 2: Preprocessing the data for GPT-3 fine-tuning
- Step 3: Compute the document & query embeddings
- Step 4: Find similar document embeddings to the query embeddings
- Step 5: Add relevant document sections to the query prompt
- Step 6: Answer the user's question based on document context
- Step 7: Prompt engineering to create an IPO Summary
We're excited to announce our new service offering: GPT-3 fine tuning as a service:
 Peter Foy
Peter Foy
Step 1: Get the data
Step 1 is easy. You can find the S-1/A we use for fine-tuning GPT-3 here.
Step 2: Preprocessing the data for GPT-3 fine-tuning
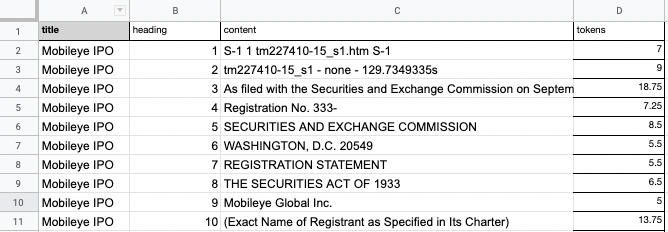
Ok next we want to process the data and prepare it for fine-tuning. To do so, we need to split the text into chunks that can be searched and retrieved seperately. As the OpenAI notebook suggests:
Sections should be large enough to contain enough information to answer a question; but small enough to fit one or several into the GPT-3 prompt. We find that approximately a paragraph of text is usually a good length, but you should experiment for your particular use case.
Done. There's definitely more work I could do in terms of build a data preprocessing pipeline that does this for manual work me, but for now, this will work fine:
Stay up to date with AI
Step 3: Compute the document & query embeddings
Next up, we're going to upload this preprocessed data and created an embedding vector for each section.
The reason we do this is to calculate similarities between the user's query and sections of the document, as the notebook highlights:
An embedding is a vector of numbers that helps us understand how semantically similar or different the texts are. The closer two embeddings are to each other, the more similar are their contents.
In addition to the document embeddings, we need a function to compute the query embeddings so we can retrieve the most relevant sections related to the question. To do so, we use the following functions from the notebook:
get_embeddingget_doc_embeddingget_query_embeddingcompute_doc_embeddings

Ok, we now have our IPO prospectus split into sections and encoded with embedding vectors. Next, we will use these embeddings to answer the user's question.
Step 4: Find similar document embeddings to the query embeddings
Now that we have both document and query embeddings, we need a function that will find the most similar document embeddings to the query embeddings so it can actually answer questions.
To do this, we use these functions from the notebook:
vector_similarityto calculate the similarity between vectorsorder_document_sections_by_query_similarityto find the query embedding for the question, and compare it against all of the document embeddings to find the most relevant sections.

Step 5: Add relevant document sections to the query prompt
Now that we've ordered document sections by query similarity, we need to construct a prompt that contains this information.
To do this, we'll use the construct_prompt function:
prompt = construct_prompt(
"What is name of the CEO?",
context_embeddings,
df
)
print("===\n", prompt)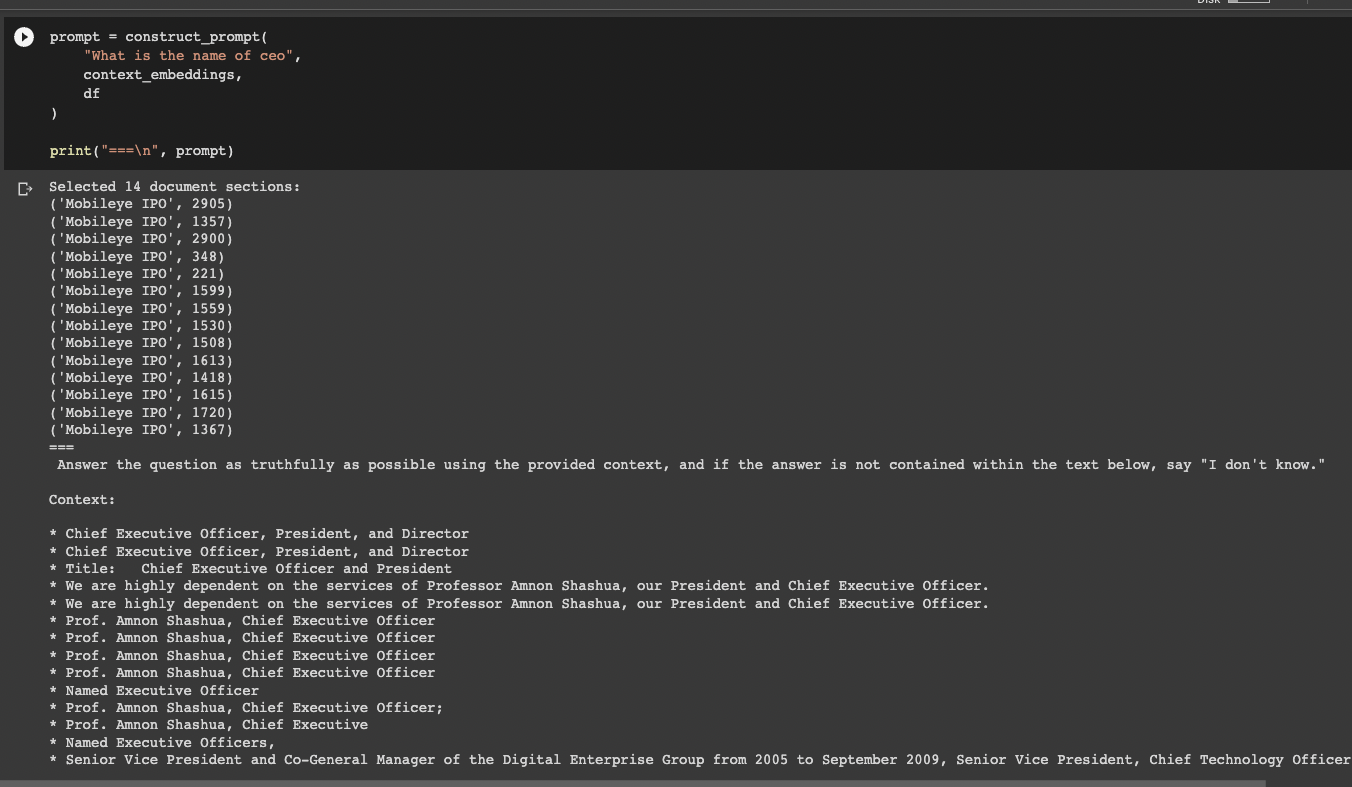
Now we can see we've found the relevant document section that contains the answer to our question, so now we just to answer the question based on this additional context.
Step 6: Answering the user's question with the Completions API
Ok to recap, we've retrieved relevant context to the user's question, we've constructed a prompt with this additional context, now we need to use the Completions API to actually answer the question.
Note that we've also set our temperature parameter to 0 to ensure GPT-3 doesn't go off and answer the question "creatively". As the docs highlight:
Higher temperatue values means the model will take more risks. Try 0.9 for more creative applications, and 0 (argmax sampling) for ones with a well-defined answer.
To answer the user's question, we just need to use our answer_query_with_context function:
answer_query_with_context("What does Mobileye do?", df, context_embeddings)
Looking good! The answer provided is from the "Company Overview" section of the prospectus which states:
Mobileye is a leader in the development and deployment of advanced driver assistance systems (“ADAS”) and autonomous driving technologies and solutions.
Step 7: Prompt engineering to create an IPO Summary
Ok, we've now fine-tuned GPT-3 to answer questions factually based on the IPO prosectus, let's now do some prompt engineering in order to output a complete IPO summary of Mobileye.
To do so, I've supplied the following questions to the fine-tuned GPT-3 (the actual prompts were a bit longer, but this gives you an idea)
- Provide an overview of Mobileye
- Tell me about the stock offering
- Who is the leadership team at Mobileye?
- Provide an overview of the competitive strengths of the company
- Provide an overview of the company's growth strategy
- Provide an overview of the ADAS and autonomous driving technology industry
- Provide an overview of the company's relationship with Intel
- Provide a summary of key financial metrics related to revenue and profitability
- Tell me about the company's cash & cash equivalents
- What are the risk factors related to the Mobileye IPO?
- Tell me about the company's go-to-market roadmap
Below is an example of the revenue & profitability prompt (pretty awesome that it's outputted in markdown table format:)
| Metric | 2021 | 2020 | 2019 | 6 Months Ended July 2, 2022 | 6 Months Ended June 26, 2021 |
|---|---|---|---|---|---|
| Revenue | $1.4B | $967M | $879M | $854M | $704M |
| Net Loss | $75M | $196M | $328M | $67M | $4M |
| Adjusted Net Income | $474M | $289M | $51M | $276M | $270M |
You can find the full Mobileye IPO summary from GPT-3 below:
Summary: Building a GPT-3 Enabled IPO Research Assistant
In this article, we discussed another real-world use case of fine-tuning GPT-3 and built an IPO research assistant. In particular, our AI research assistant was trained on Mobileye's IPO prospectus and told to only answer factually based on this additional context.
To do this, the steps we took include:
- Step 1: Get the data (IPO prospectus)
- Step 2: Preprocessing the data for GPT-3 fine-tuning
- Step 3: Compute the document & query embeddings
- Step 4: Find similar document embeddings to the query embeddings
- Step 5: Add relevant document sections to the query prompt
- Step 6: Answer the user's question based on document context
- Step 7: Prompt engineering to create an IPO Summary
The exciting part about this project is seeing the potential of GPT-3 to summarize and answer questions about long, boring legal documents. Also, given the amount of this type of text-heavy document in finance, the use cases of fine-tuning GPT-3 are quite limitless.
Of course, if you're actually investing in IPOs you probably want to read through the actual prospectus, but having an AI assistant is certainly valuable for preliminary research.




