

OpenAI recently introduced Structured Outputs in their API, solving a key challenge that unlocks many new use cases. In this guide, let's look at what structured outputs are, how to get started with them, and an example use case.
What are Structured Outputs?
OpenAI had previously released JSON mode, which was a useful building block that allowed you to reliably output JSON from the API. The issue with JSON mode is that it didn't always guarantee that the model would conform to a specific, developer-provided schema.
As OpenAI writes:
Structured Outputs solves this problem by constraining OpenAI models to match developer-supplied schemas and by training our models to better understand complicated schemas.
In other words, you can use Structured Outputs to reliably generate structured data from unstructured inputs. While this was somewhat feasible before with prompting and parsing responses, the reliability wasn't always there.
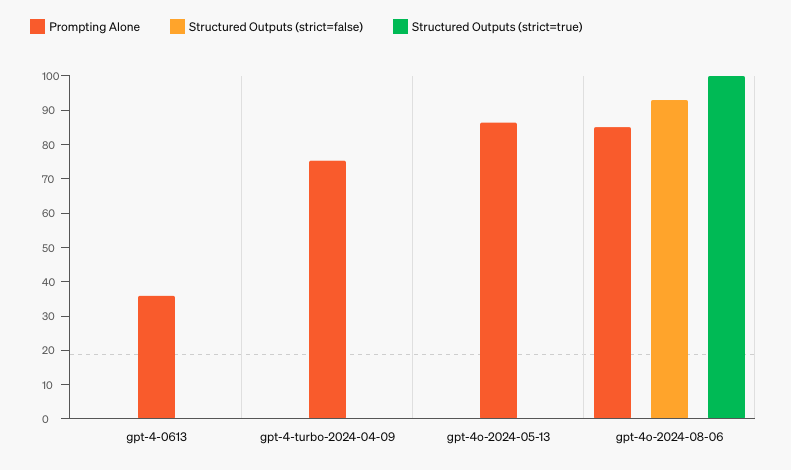
Now, with Structured Ouputs, you can build AI agents that are much more flexible and reliable and output responses in the exact format you need. With their evals, OpenAI shows that Structured Outputs scores a perfect 100% in producing complex JSON schema...not bad.
Getting Started with Structured Outputs
Now that we know what structured outputs are and their importance for developers, let's look at how to get started with them.
For this example, we'll look at extracting companies mentioned in earnings call transcripts, along with the associated quote from the speaker.
Setting Up the Environment
First, we need to install the following packages into our notebook if you haven't already:
pip install openai pydantic requests
Next, import the required libraries in your Python script:
from pydantic import BaseModel
import openai
import requests
import json
Fetching Earnings Call Transcripts
For this example, we'll retrieve the earnings call transcript of a specific company for a given year and quarter. The transcript will serve as our unstructured data, and we'll extract the relevant tickers mentioned using structured outputs.
Here’s a simple function to fetch the earnings call transcript using the Financial Modeling Prep API:
def get_earnings_transcript(ticker, year, quarter):
"""Fetch the earnings call transcript."""
url = f"https://financialmodelingprep.com/api/v3/earning_call_transcript/{ticker}?year={year}&quarter={quarter}&apikey={FMP_API_KEY}"
response = requests.get(url)
if response.status_code == 200:
return response.json()[0]['content']
else:
raise Exception("Failed to retrieve transcript")
Note: you’ll need to replace FMP_API_KEY with your actual API key from Financial Modeling Prep.
Defining the Structured Output Schema
Next, in order to ensure the model’s output adheres to a specific structure we define a schema using Pydantic’s BaseModel.
In this example, the model will extract details about companies mentioned in the transcript, including their name, ticker symbol, relevant quotes, and the speaker.
class Company(BaseModel):
name: str
ticker: str
quote: str
speaker: str
class CompanyResponse(BaseModel):
companies: list[Company]
This schema ensures that the GPT output will always include the necessary fields, making it much more reliable to work with the output data in an application.
Extracting Company Mentions from the Transcript
Now that we have our schema, we can define a function to process the transcript and extract the relevant information using the OpenAI API:
def extract_companies_from_transcript(transcript):
messages = [
{"role": "system", "content": "You are an expert on reading earnings transcripts. Your task is to find all companies explicitly mentioned in the transcript, extract their ticker symbols, pull out the exact comments and quotes related to the companies, and identify the speaker. Do not include the company hosting the call or any company mentioned solely due to its association with an analyst."},
{"role": "user", "content": transcript}
]
completion = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
max_tokens=4096,
messages=messages,
response_format=CompanyResponse
)
return completion.choices[0].message.parsedThis function sends the transcript to the OpenAI API, which then extracts the companies mentioned along with their related information, all while adhering to the schema we defined.
Handling the Output and Displaying Results
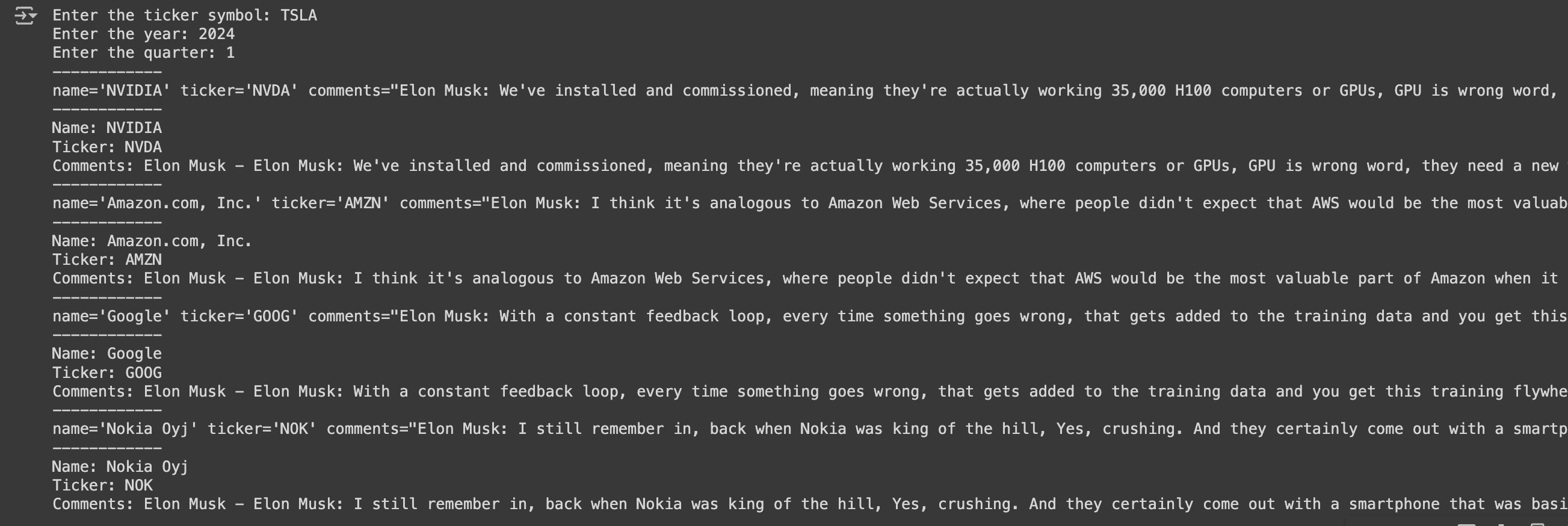
Finally, let’s create a main function to tie everything together. This function will prompt the user for the ticker symbol, year, and quarter, fetch the transcript, extract the company data, and then display the results.
def main():
ticker = input("Enter the ticker symbol: ")
year = input("Enter the year: ")
quarter = input("Enter the quarter: ")
try:
transcript = get_earnings_transcript(ticker, year, quarter)
message = extract_companies_from_transcript(transcript)
if message:
for company in message.companies:
print(company)
print(f"Name: {company.name}")
print(f"Ticker: {company.ticker}")
print(f"Quotes: {company.spaker} - {company.comments}")
else:
print(message.refusal)
except Exception as e:
print(f"An error occurred: {e}")
if __name__ == "__main__":
main()Here we can see the model is now correctly parsing the transcript and outputting the message exactly how we've defined it.
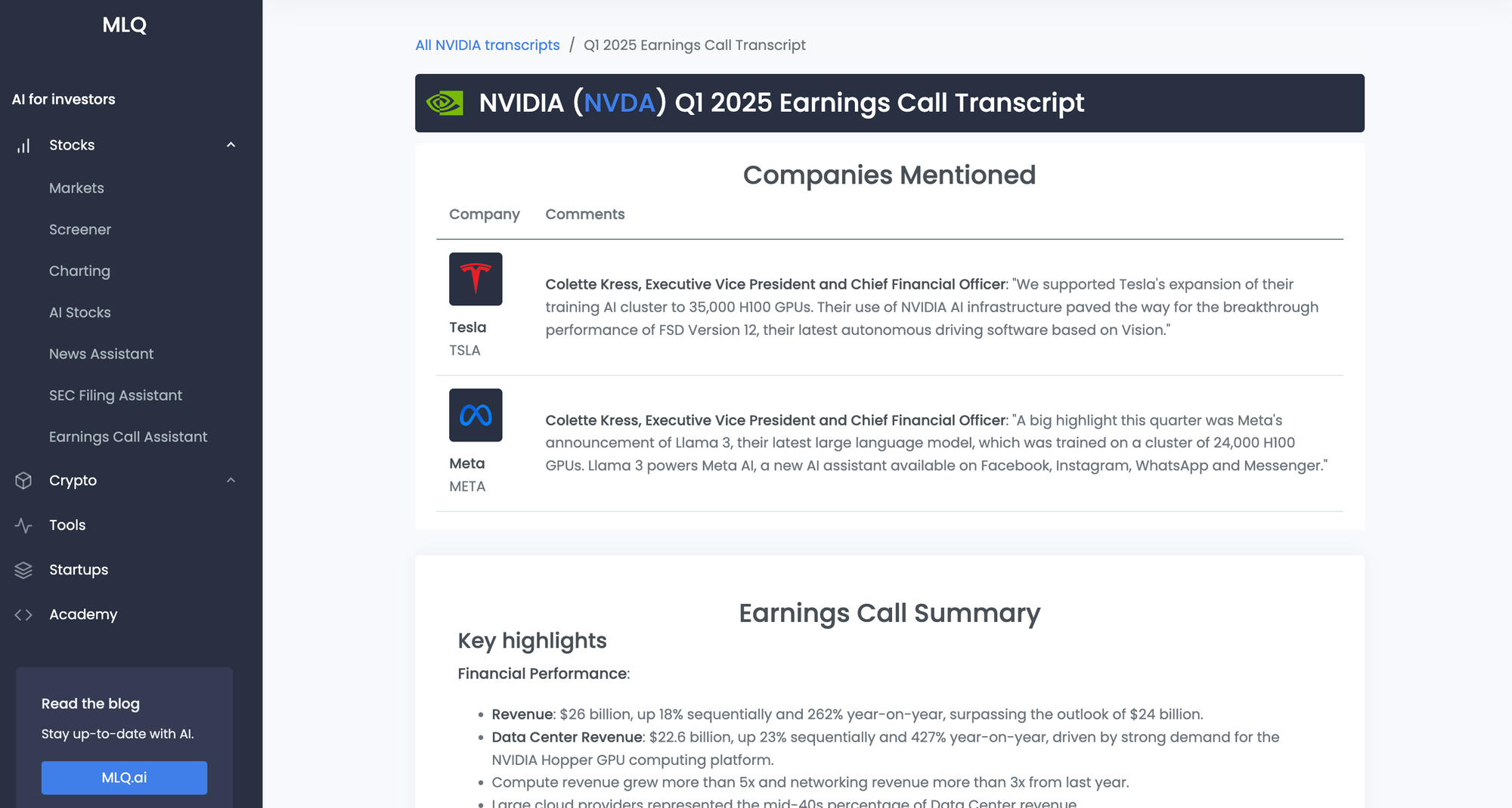
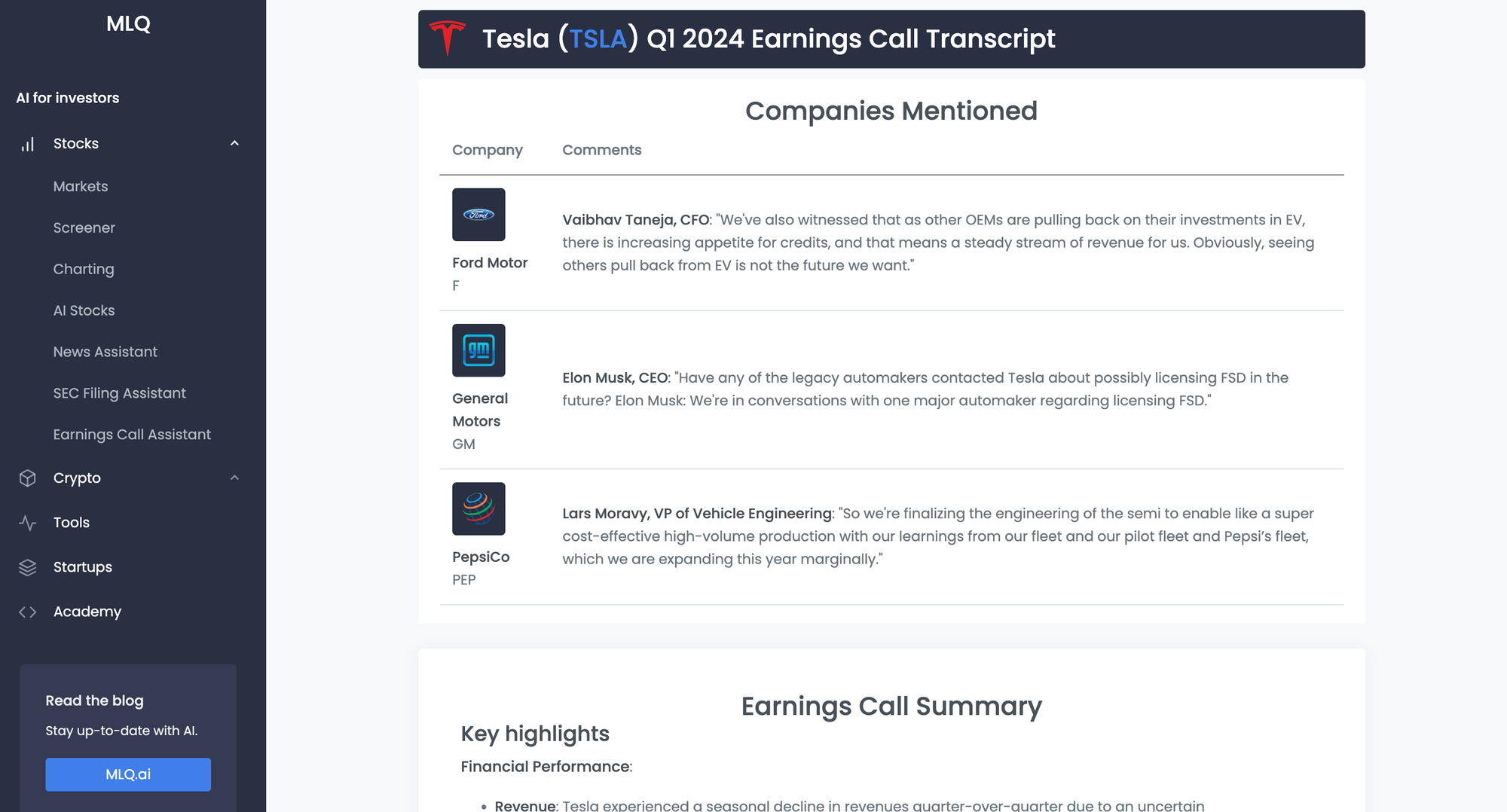
Companies Mentioned in Earnings Calls
Since we've already built an Earnings Call Analyst agent at MLQ, we've now added this ability to extract companies mentioned directly into our app.
You can try this out for yourself here or extract companies and summaries on any earnings transcript page with MLQ premium. Check out these examples:
Summary: Structured Outputs
In this guide, we walked through a practical example of how to use Structured Outputs in the OpenAI API to extract structured data from unstructured earnings call transcripts.
By defining a schema with Pydantic, we ensured that the AI's output adhered to a strict format, making the data easier to handle and more reliable.
For more advanced use cases, such as combining Structured Outputs with function calling, check out OpenAI's docs to learn more.




