

In this article, we're going to discuss several fundamental concepts of reinforcement learning including Markov decision processes, the goal of reinforcement learning, and continuing vs. episodic tasks.
This article is based on notes from Week 2 of this course on the Fundamentals of Reinforcement Learning and is organized as follows:
- Introduction to Markov Decision Processes
- The Dynamics of an MDP
- The Goal of Reinforcement Learning & Episodic Tasks
- Continuing Tasks
Stay up to date with AI
Introduction to Markov Decision Processes
In our previous article on Estimating the Action-Function, we introduced the k-armed bandit problem, which serves as a simplified version of the RL problem that involves sequential decision making and evaluative feedback.
The k-armed bandit problem, however, doesn't include many aspects of real-world problems. In particular, the agent is presented with the same situation at each timestep and the optimal action is always the same.
In reality, however, different situations arise that call for different actions. These actions can also affect the potential rewards an agent can receive in the future.
A Markov decision process captures and formalizes these two aspects of real-world problems.
A key difference between bandits and Markov decision processes is that the agent must consider the long-term impact of its actions.
In a Markov decision process, as the agent takes actions its situation changes as it—these situations are referred to as the state.
In each state, the agent selects and action, after which the environment changes into a new state and produces a reward.
We can formalize this interaction as a general framework:
- The agent and the environment interact at discrete time steps $t$
- At each time $t$ the agent receives a state $S_t$ from the environment from a set of possible states $\mathcal{S}$, written as $S_t \in \mathcal{S}$
- Based on the state, the agent selects an action $A_t$ from a set of possible actions $\mathscr{A}$, which is written as $A_t \in \mathscr{A}(S_t)$
- After the agent takes an action, it is then in state $S_{t+1}$
- The environment also provides a scalar reward $R_{t+1}$ that is taken from a set of possible rewards $\mathscr{R}$, written as $R_{t+1} \in \mathscr{R}$
The diagram below from Sutton & Barto's textbook Reinforcement Learning: An Introduction summarizes the agent-environment interaction in the framework of a Markov decision process:
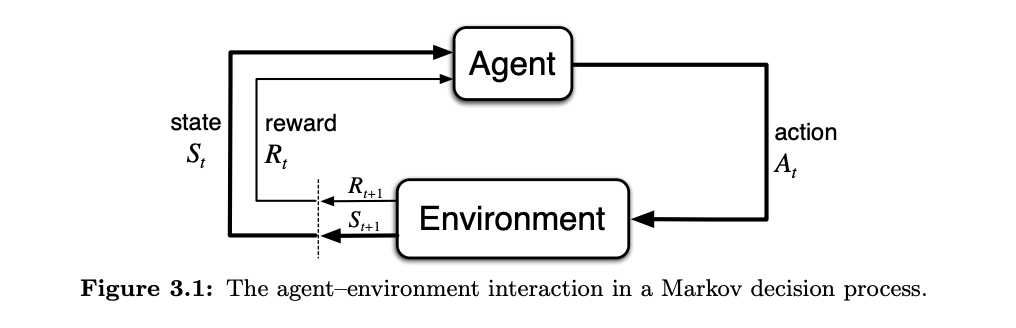
In summary, the actions an agent takes influences immediate rewards as well as future states and future rewards.
The Dynamics of an MDP
Similar to the bandits problem, the outcomes of an MDP are stochastic, so we use probabilities to express it.
When the agent takes an action in a state, there are many possible next states. We can formalize this transition dynamics function, $p$, as follows:
$$p(s', r| s, a)$$
Given a state $s$ and action $a$, $p$ provides the joint probability of the next state $s'$ and the reward $r$.
Since $p$ is a probability distribution, it must be non-negative and its sum over all possible next states and rewards must equal 1.
The future state and reward only depend on the current state and action. This is referred to as the Markov property, which says that:
The present state contains all the information necessary to predict the future.
In summary, MDPs provide a general framework for sequential decision-making and the dynamics are described as a probability distribution.
This MDP formalism is both abstract and flexible, meaning it can be applied to a wide variety of sequential decision-making problems.
The Goal of Reinforcement Learning & Episodic Tasks
In the context of reinforcement learning, the goal of an agent is to maximize future reward.
In this section we will define how rewards relate to the goal of an agent and how to identify episodic tasks.
In an MDP, agents can't simply maximize immediate reward. An agent must then consider how immediate actions will influence future rewards.
We can formalize the goal of maximizing total future reward as follows:
$$G_t \doteq R_{t+1} + R_{t+2} + R_{t+3} +...$$
The reward $G_t$ is the sum of rewards obtained after at timestep $t$.
The reward $G_t$ is a random variable since the dynamics of an MDP can be stochastic. This is due to both the randomness of individual rewards and the state transitions.
For this reason, we maximize the expected return:
$$\mathbb{E}[G_t] = \mathbb{E}[R_{t+1} + R_{t+2} + R_{t+3} +...R_T]$$
For this to be well defined, the sum of rewards must be finite.
When the agents interaction with the environment ends, it is broken down into what are referred to as episodes.
Each episode begins independently of how the previous one ended and the agent is reset to the starting state. Each episode also has a terminal state, denoted as $R_T$, and are called episodic tasks.
Continuing Tasks
In many real-world problems, the agent-environment interaction continues without a finite end.
In reinforcement learning, these problems are referred to as continuing tasks.
The difference between episodic and continuing tasks can be summarized as follows.
Episodic Tasks:
- Episodic tasks naturally break up into episodes
- Each episode ends in a terminal state
- Episodes are independent
- The return at timestep $t$ is the sum of rewards until the terminal state
Continuing Tasks:
- Interaction between agents and the environment goes on continually
- There is no terminal state
An example of a continuing task is a smart thermostat that's goal is to regulate the temperature of the building since the thermostat never stops interacting with the environment.
We can formulate the return of continuing tasks by making $G_t$ finite, specifically by discounting the rewards in the future by the discount rate $\gamma$, where $0 \leq \gamma < 1$.
The return formulation can then be modified to include discounting:
$$G_t \doteq R_{t+1} + \gamma R_{t+2} + \gamma^2R_{t+3} + ... + \gamma^{k-1}R_{t+k} ...$$
The effect of discounting is that immediate rewards contribute more to the sum than future rewards.
We can summarize this equation as follows, which is guaranteed to be finite:
$$ = \sum\limits_{k=0}^{\infty} \gamma^k R_{t+k+1}$$
The effect of $\gamma$ on an agents behavior is that a lower $\gamma$ will cause the agent to focus on short-term rewards, whereas a $\gamma$ approaching 1 will make the agent future rewards into account more strongly.
If we factor out $\gamma$, we can write this returns equation recursively as:
$$G_t = R_{t+1} + \gamma G_{t+1}$$
Summary: Markov Decision Processes and Reinforcement Learning
In this article, we discussed Markov decision processes can be used to formulate many problems in reinforcement learning.
MDPs formalize the problem of an agent interacting with an environment in discrete time steps.
At each time step, the agent observes the current state $S_0$. Based on the state, the agent chooses an action $A_0$, and the environment transitions to a new state $S_1$ and provides a reward $R_1$.
In MDPs, the action that an agent selects affects not only the immediate rewards, but also the future states and rewards.
The goal of reinforcement learning is to maximize cumulative expected reward, which involves balancing immediate rewards with longer-term expected rewards.
This goal is formalized with the expected discounted sum of future rewards $ = \sum\limits_{k=0}^{\infty} \gamma^k R_{t+k+1}$.
In the case of continuing tasks, by discounting future rewards with $0 \leq \gamma > 1$ we can guarantee that the return remains finite. By adjusting $\gamma$, this affects how much the agent values short-term vs. long-term rewards.
In summary, the first step of solving a problem with reinforcement learning is to formalize it as a Markov decision process.




