Python is one of the fastest-growing programming languages for applied finance and machine learning.
In this article, we'll look at how you can build models for time series analysis using Python. As we'll discuss, time series problems have several unique properties that differentiate them from traditional prediction problems.
The following is based on notes from this course on Python for Financial Analysis and Algorithmic Trading as is organized as follows:
- Pandas for Time Series Data
- Time Series Analysis Techniques
1. Pandas for Time Series Data
To get started, let's review a few key points about Pandas for time series data.
The majority of financial datasets will be in the form of a time series, with a DateTime index and a corresponding value.
Pandas has special features for working with time-series data, including:
- DateTime index
- Time resampling
- Time shifts
- Rolling and expanding
DateTime Index
Often in financial datasets the time and date won't be a separate column, but instead will be the index.
Built-in Python libraries already exist for dates and times exist, so without installing any additional libraries we can use:
from datetime import datetimeThis allows us to create timestamps or specific date objects.
Let's create a few variables:
my_year = 2021
my_month = 5
my_day= 1To use Python's built-in datetime functionality we can use:
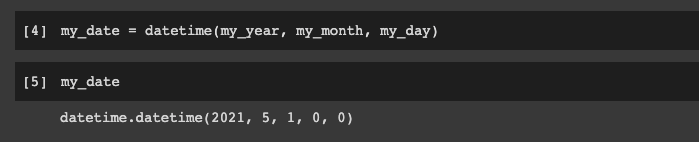
my_date = datetime()As we can see, this takes in year, month, day, and time—let's pass these arguments in:
my_date = datetime(my_year, my_month, my_day)
Let's take a look at this datetime object:
Let's look at how we can convert a list of two datetime objects to an index:
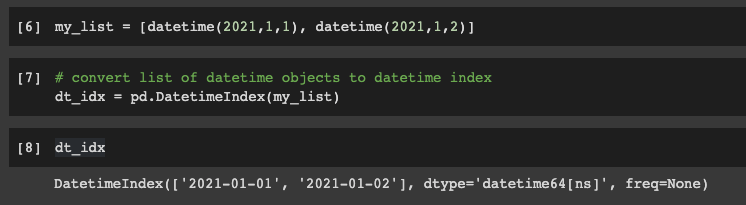
my_list = [datetime(2021,1,1), datetime(2021,1,2)]
We can convert a NumPy array or list to an index with the following:
dt_idx = pd.DatetimeIndex(my_list)
Time Resampling
When dealing with financial datasets we usually get data that has a DateTime index on a smaller scale (day, hour, minute, etc.).
For the purpose of analysis, however, it is often a good idea to aggregate data based on some frequency (monthly, quarterly, etc.).
You might think that GroupBy can solve this, but it isn't made to understand things like business quarters, the start of a year, or the start of a week.
Luckily, Pandas has frequency sampling tools built-in to solve this.
To understand this, let's take a look at stock market data for Tesla from May 1st, 2020 - May 1st, 2021, which can be downloaded from Yahoo Finance.
Here are our imports:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inlineNow let's upload the data to Google Colab:
from google.colab import files
uploaded = files.upload()Then we'll read in our CSV and take a look at the data
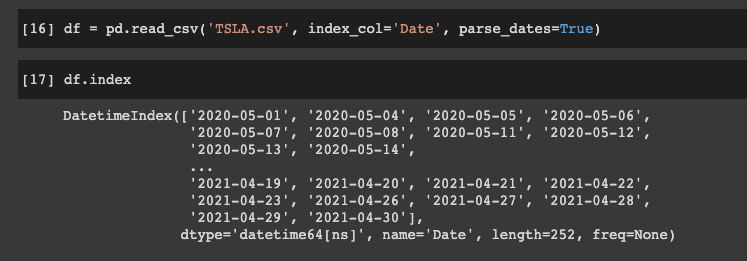
df = pd.read_csv('TSLA.csv')
The Date column is what we want to be the index, so we convert it to a datetime index with pd.to_datetime() and passing in the Series:
df['Date'] = pd.to_datetime(df['Date'])
If we call df.info() we can see it is now a datetime object:

Let's now set the Date column as the index:
df.set_index('Date', inplace=True)
To simplify this, we could have also just set the index_col='Date' and set parse_dates=True.
We can then check the index with df.index:
To do any sort of time resampling we need a datetime index, and then we can resample the DataFrame with df.resample() and then we pass in a rule.
The rule is just how we want to resample the data, and there are keywords for every type of time series offset strings, which you can read about more in the documentation.
The rule is essentially acting as a GroupBy method specifically for time series data.
Let's look at an example of the A rule, which stands for "year-end frequency" and we will get the mean value based off the resampling:
# mean value based off the end of the year resampling
df.resample(rule='A').mean()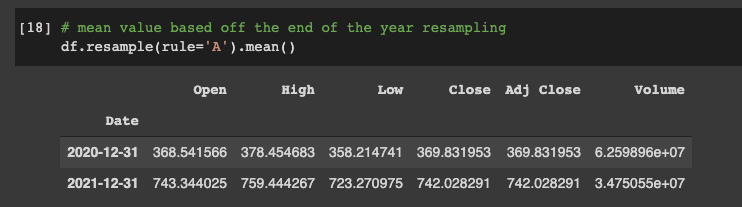
In this example everything before 2018-12-31 had a mean Open value of $316.12.
Everything in between 2018-12-31 and 2019-12-31 had a mean of $291.44.
We can then get the mean value after quarterly resampling with the Q rule:
# quarterly resampling
df.resample(rule='Q').mean()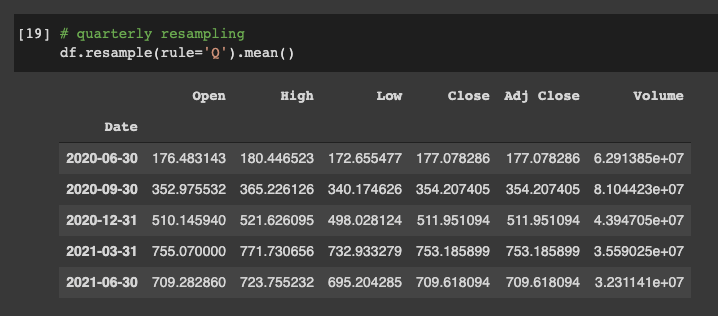
Stay up to date with AI
Time Shifts
Often time series forecasting models require us to shift our data forward and backward with a certain amount of time steps.
Pandas makes this easy to do with the .shift() method.
To demonstrate this let's look at the Tesla CSV again, which we can see that it has daily data.
If we ever want to shift our time period up by one step we can use:
df.shift(periods=1).head()
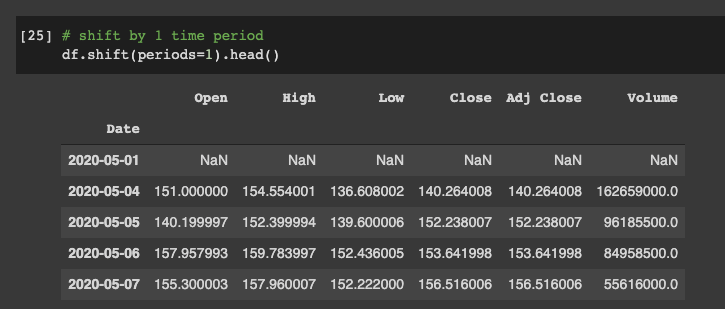
After this we can see that we no longer have any values for our first time period.
We can also shift the time period backwards by using -1 for our periodsargument.
Pandas Rolling & Expanding
We can use pandas' built-in rolling method, for example if we want to create a rolling mean based off a given time period.
When dealing with financial data often the daily data can be quite noisy.
To account for this, we can use the rolling mean (otherwise known as the Moving Average) to generate a signal about the general trend of the data.
Let's plot our daily data with:
df['Open'].plot(figsize=(16,6))
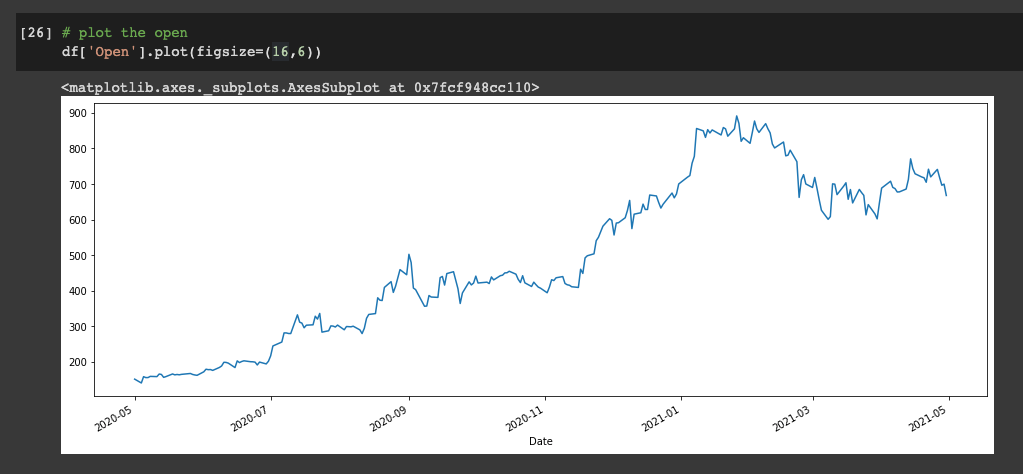
Let's now average this out by the week - we can either get the Moving Average on a particular column or Series, or on the entire DataFrame with the .rolling()method.
To do this we pass in 7 as the window and then add the aggregate function .mean():
df.rolling(7).mean().head(14)
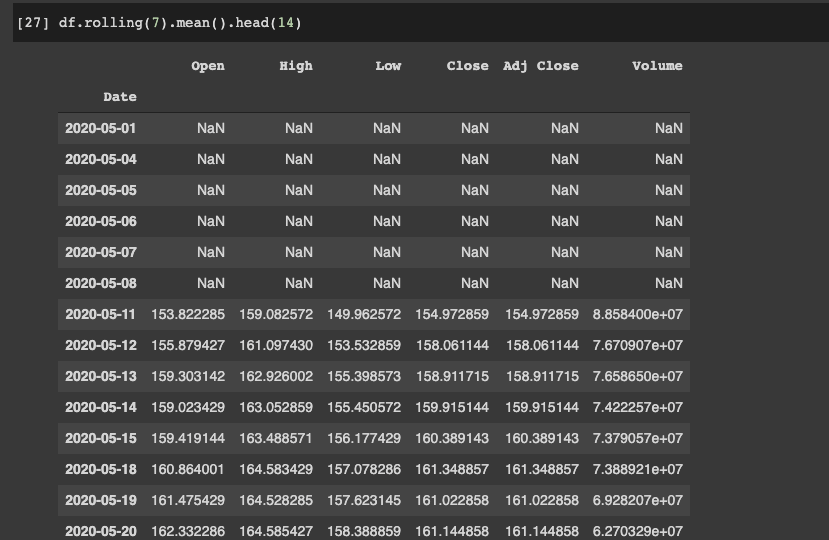
We can see the first 6 values are null, and the 7th value is the mean of the first 6 rows.
Let's now plot the Open column vs. the 7-day moving average of the Close column:
df['Open'].plot()
df.rolling(7).mean()['Close'].plot(figsize=(16,6))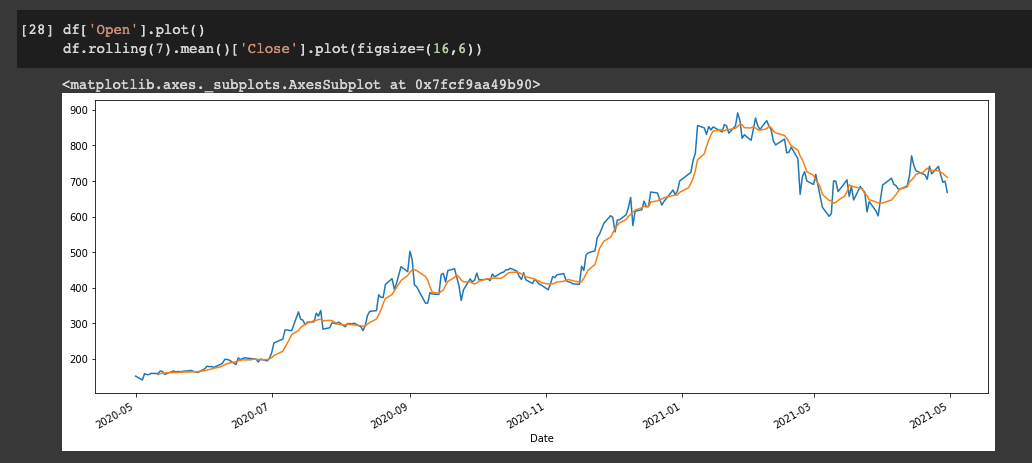
When we look at this plot we see that the blue line is the Open price column, and the orange line is the rolling 7-day Close price.
Now, what do we do when we take to take into account everything from the start of the time series to the rolling point of the value?
For example, instead of just taking into account a 7-day rolling window, we take into account everything since the beginning of the time series to where we are at that point.
To do this we use the .expanding() method:
df['Close'].expanding().mean().plot(figsize=(16,6))
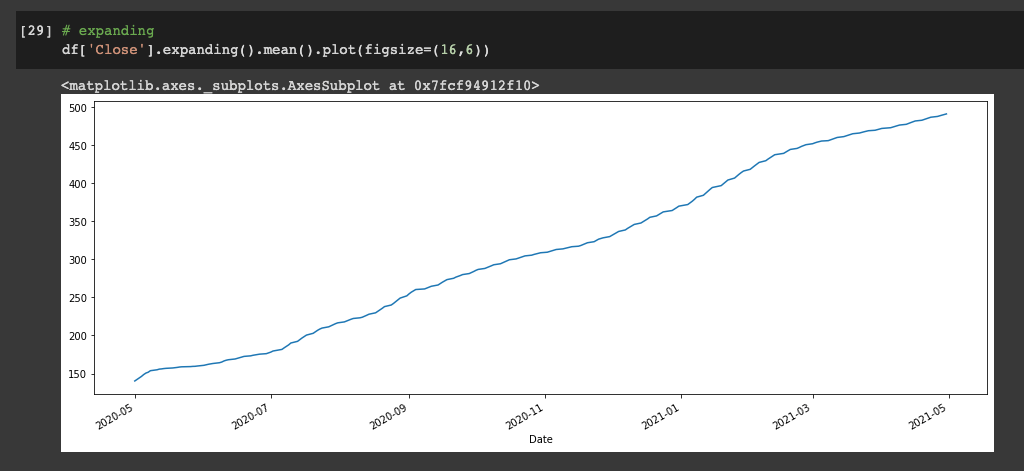
So what does this plot represent?
At each time step on the x-axis, what is shown on the y-axis is the value of everything that came before it averaged out.
Bollinger Bands
We'll look at more fundamental & technical analysis later, but one closely related topics to .rolling() are Bollinger Bands so let's briefly discuss them.
Bollinger Bands are volatility bands placed above and below a moving average, where the volatility is based off the standard deviation which changes as volatility increases or decreases.
The bands widen when volatility increases and narrow when it decreases.
Let's look at how we can code Bollinger Bands with Pandas, here are the steps we need to take.
We need to create 3 columns and then we plot them out:
- The first column is the Closing 20-day Moving Average
- Then create the upper band equal to 20-day MA + 2x the standard deviation over 20 days
- The lower band is equal to 20-day MA - 2x STD over 20 days
# Close 20 MA
df['Close: 20 Day Mean'] = df['Close'].rolling(20).mean()
# Upper = 20MA + 2*std(20)
df['Upper'] = df['Close: 20 Day Mean'] + 2*(df['Close'].rolling(20).std())
# Lower = 20MA - 2*std(20)
df['Lower'] = df['Close: 20 Day Mean'] - 2*(df['Close'].rolling(20).std())
# Plot Close
df[['Close','Close: 20 Day Mean','Upper','Lower']].plot(figsize=(16,6))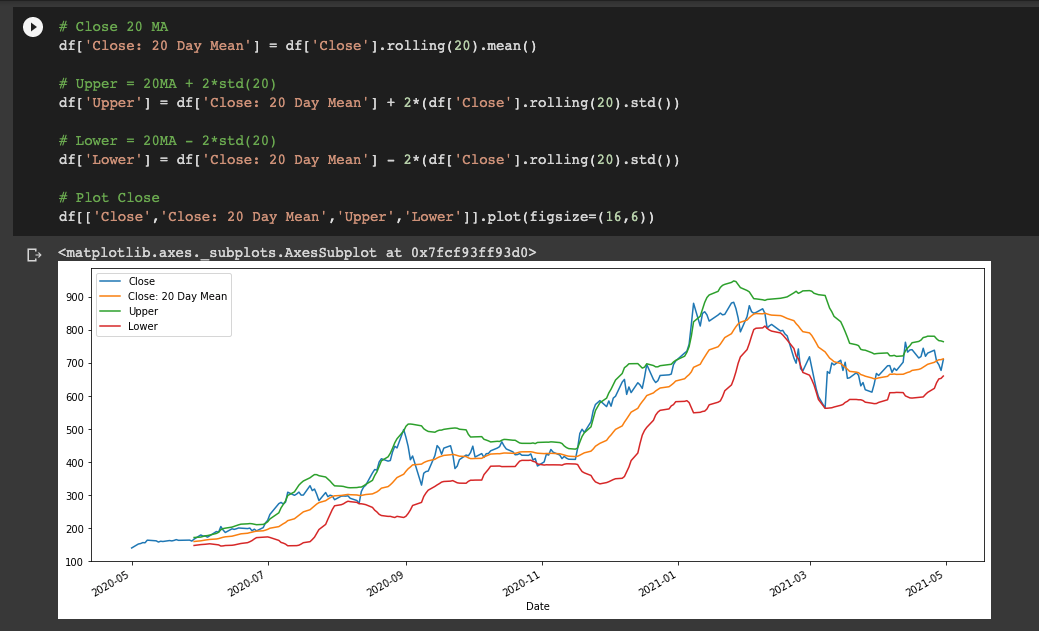
2. Time Series Analysis
Now that we've learnt about Pandas for time series data, let's shift focus on several time series analysis techniques.
Time series data has special properties and a different set of predictive algorithms than other types of data.
We'll discuss the following topics:
- Introduction to Statsmodel
- ETS Models & Decomposition
- EWMA Models
- ARIMA Models
Introduction to Statsmodel
The most popular Python library for dealing with time series data is StatsModels:
statsmodels is a Python module that provides classes and functions for the estimation of many different statistical models, as well as for conducting statistical tests, and statistical data exploration.
StatsModels is heavily inspired by the statistical programming language R.
It allows users to explore data, estimate statistical models, and perform statistical tests.
Let's look at the time series analysis tsa module.
First we'll import statsmodels.api as sm and then load a dataset that comes with the library and then we'll load the macrodata dataset:
# import dataset with load_pandas method and .data attribute
df = sm.datasets.macrodata.load_pandas().data
df.head()
We can check out what is in the dataset with the .NOTE attribute - this one is about economic data for the US.
Let's now set the year to be the time-series index:
index = pd.Index(sm.tsa.datetools.dates_from_range('1959Q1','2009Q3'))
df.index = indexNow that the year is a time series index, let's plot the realgdp column:
df['realgdp'].plot()
Let's do some analysis using statsmodel to get the trend of the data, and in this case we're going to use the Hodrick-Prescott filter:
sm.tsa.filters.hpfilter(df['realgdp'])
This returns a tuple of the estimated cycle in the data and the estimated trend in the data.
We're then going to use tuple unpacking to get the trend and plot on top of this
# let's use tuple unpacking to get this trend and plot it on top of this
gdp_cycle, gdp_trend = sm.tsa.filters.hpfilter(df['realgdp'])
# add a a column for the trend
df['trend'] = gdp_trend
# plot the real gdp & the trend
df[['realgdp','trend']].plot()
ETS Models with StatsModels
ETS model stands for Error-Trend-Seasonality.
Let's take a look at the ETS components of a time series dataset.
ETS models take each of the terms (Error-Trend-Seasonality) for smoothing purposes - and may add them, multiply them, or leave some of them out of the model.
Based off these key factors we can create a model to fit our data.
So how can we break down a time series into each of these terms?
Time Series Decomposition with ETS is a method of breaking down a time series into these components.
Here's how we would do ETS decomposition for the TSLA CSV:
from statsmodels.tsa.seasonal import seasonal_decompose
result = seasonal_decompose(df['Adj Close'], model='additive', freq=12)And then we can plot out the components, for example the trend:
result.trend.plot()

And then we can plot all the results:
result.trend.plot()

EWMA Models
EWMA stands for Exponentially Weighted Moving Average.
We saw that with pd.rolling() we can create a simple model that describes a trend of a time series - these are referred to as Simple Moving Averages (SMA).
A few of the weaknesses of SMA's include:
- A smaller windows will lead to more noise, rather than signal
- It will always lag the size of the window
- It will never reach the peak or valley of the data due to averaging
- It doesn't inform us about future behavior, it really just describes trends in the data
- Extreme historical values can skew the SMA
To recap, here's how we can calculate the 30-day SMA for TSLA:
# create 1 month SMA off of Adj Close
df['30 Day SMA'] = df['Adj Close'].rolling(window=30).mean()
# plot SMA & Adj Close
df[['Adj Close', '30 Day SMA']].plot(figsize=(10,8))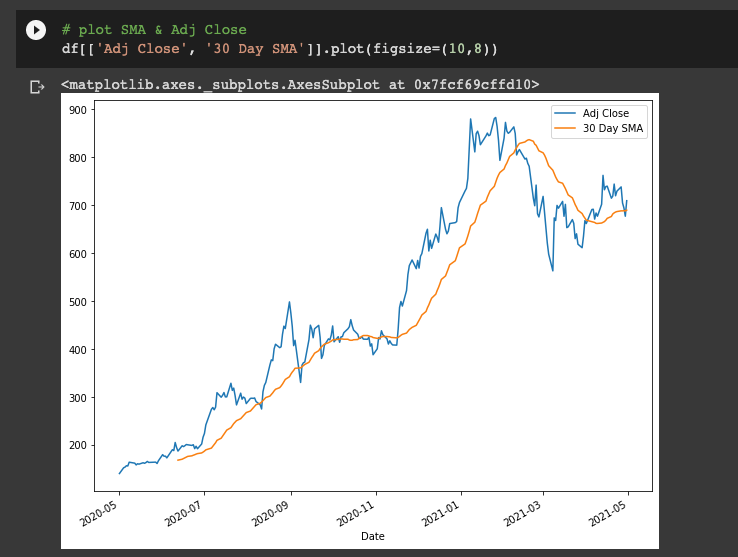
Exponentially Weighted Moving Averages solve some of these issues, in particular:
- EWMA allows you to reduce the lag time from SMA and puts more weight on values that occur more recently
- The amount of weight applied to the recent values depends on the parameters used in the EWMA and the number of periods in the window size
Here's how we can create an EWMA model:
# create EWMA
df['EWMA-30'] = df['Adj Close'].ewm(span=30).mean()
# plot EWMA
df[['Adj Close', 'EWMA-30']].plot(figsize=(10,8))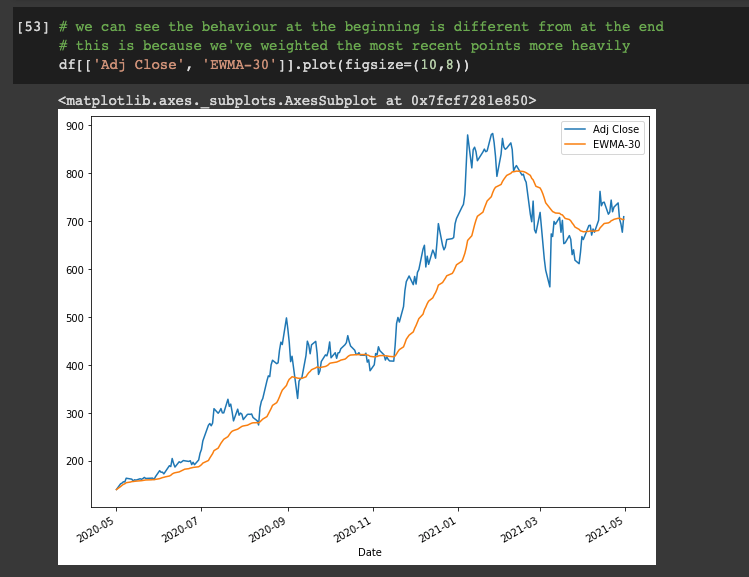
We can see the behavior at the beginning is different from at the end - this is because we've weighted the most recent points more heavily.
ARIMA
Although ARIMA models are one of the most common time series models, they often don't work well with historical market data so we won't cover them here.
If you want to learn more about ARIMA models check out this article from Machine Learning Mastery.
Summary: Time Series Analysis with Python
In this guide we reviewed time series analysis for financial data using Python.
We saw that time series problems are difference from traditional prediction problems and looked at Pandas for time series data, as well as several time series analysis techniques.
The statsmodel library is the most popular Python library for dealing with time series data is. We then discussed how we can use statsmodels for ETS (Error-Trend-Seasonality) models.
Finally, we looked at how to use Simple and Exponentially Weighted Moving Averages (SMA & EWMA) for time series analysis.