

When you start working with large language models like GPT-3 and now GPT-4, you'll start to notice how important your input prompts are for getting the desired result.
At first, if the LLM fails at a particular task, you may assume the model is simply incapable of performing the task. However, for many more complex tasks that involve logical reasoning, there are a few prompt engineering techniques we can use to try and improve performance.
In this guide, we'll go through OpenAI's Cookbook on Techniques to Improve Reliability and review key concepts and techniques, including:
- Why GPT-3 fails on certain tasks
- How to improve reliability on complex tasks
- Splitting complex tasks into simpler tasks
- Prompting the model to explain its reasoning before answering
- GPT-3 fine-tuning to improve performance
Let's get started.
Stay up to date with AI
Why GPT-3 fails on certain tasks
First off, it's important to note that GPT-4 may solve many of the complex tasks that OpenAI mentions GPT-3 fails at, although it's still worth understanding these prompt engineering techniques as GPT-4 isn't perfect either.
That said, given that GPT-3 is essentially a highly advanced "next-word predictor", one of the first reasons it may get the wrong answer is that the task is too complex to do in the time it takes to calculate and predict the next token.
This means the first step we try when given a more complex task is to simply ask add the following to your prompt:Let's think step by step.
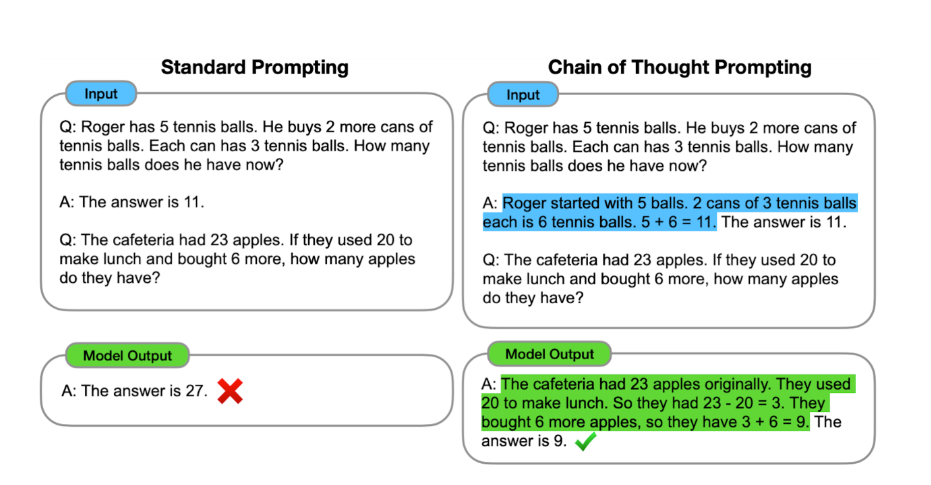
In the example OpenAI provides, text-davinci-002 struggles with a basic math problem, although I tested ith with GPT-3.5 and it gets it right without this trick, but is still a good one to keep in mind, as OpenAI writes:
On a benchmark of word math problems, the Let's think step by step trick raised GPT-3's solve rate massively, from a worthless 18% to a decent 79%!How to improve reliability on complex tasks
When it comes to improving reliability with prompt engineering, OpenAI provides the following recommendations:
- Provide clearer instructions
- Split complex tasks into simpler tasks
- Prompt the model to explain its reasoning before answering
- Ask the model to provide justifications of several possible answers, and then synthesize
- Ask the model to generate multiple outputs and then choose the best possible one
- Use fine-tuning to maximize performance
Let's look at a few of these approaches in more detail.
Splitting complex tasks into simpler tasks
First off, we've got an example from the game Clue. I tested the example below and was actually quite surprised that GPT 3.5 wasn't able to solve this...
Use the following clues to answer the following multiple-choice question.
Clues:
1. Miss Scarlett was the only person in the lounge.
2. The person with the pipe was in the kitchen.
3. Colonel Mustard was the only person in the observatory.
4. Professor Plum was not in the library nor the billiard room.
5. The person with the candlestick was in the observatory.
Question: Was Colonel Mustard in the observatory with the candlestick?
(a) Yes; Colonel Mustard was in the observatory with the candlestick
(b) No; Colonel Mustard was not in the observatory with the candlestick
(c) Unknown; there is not enough information to determine whether Colonel Mustard was in the observatory with the candlestick
Solution: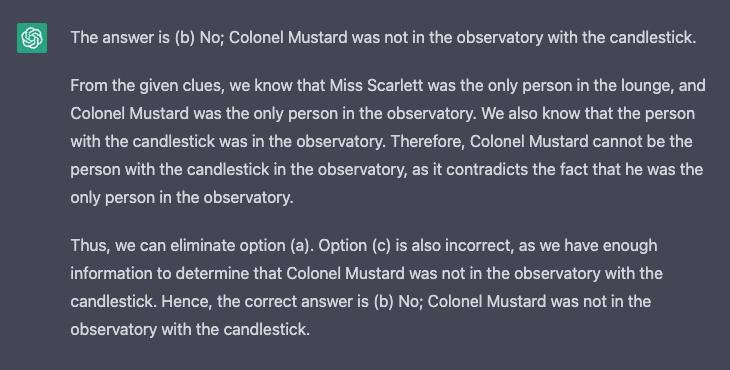
Incorrect GPT 3.5...interesting that it's not able to pick up on clues 3 and 5 to reach the correct answer of A.
Before we try and split this up into simpler tasks, let's see if GPT-4 can solve this...
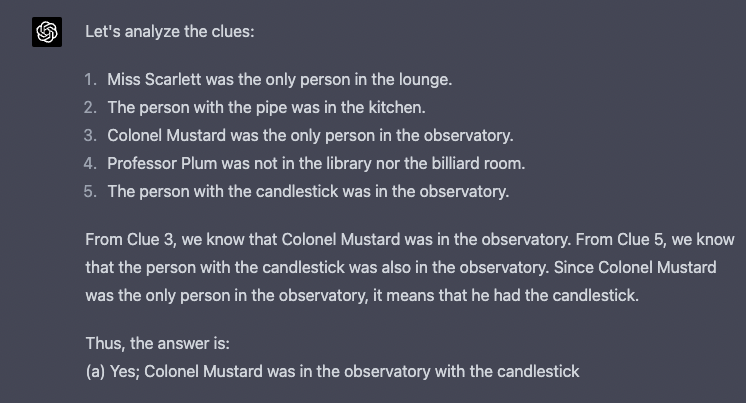
Success! This is actually quite interesting because it looks like with GPT-4 they may have used this prompt engineering technique behind the scenes in order to have the model split the task up into smaller tasks.
First, it analyzes the clues, then takes each clue into consideration, then answers.
Ok, let's use this insight and go back to GPT 3.5 with the same clues, just an updated pre-prompt and solution prompt:
Use the following clues to answer the following multiple-choice question, using the following procedure:
(1) First, go through the clues one by one and consider whether the clue is potentially relevant
(2) Second, combine the relevant clues to reason out the answer to the question
(3) Third, map the answer to one of the multiple choice answers: either (a), (b), or (c)Solution:
(1) First, go through the clues one by one and consider whether the clue is potentially relevant:
Interestingly, it still took GPT-3.5 a few tries to get this right. Without changing the prompt, I just re-ran it several times in new chats and it finally got the right answer.
Ok, so we know this is a simple useful technique, but not perfect.
Let's go onto door number 2 in our prompt engineering toolkit.
 Peter Foy
Peter Foy
Prompting the model to explain its reasoning before answering
As OpenAI highlights, another powerful prompt engineering technique to improve reliability is asking the model to gradually explain its reasoning before reaching an answer, in other words, "thinking out loud".
Zero-Shot Prompting
As this paper called Large Language Models are Zero-Shot Reasoners highlights, the simple "let's think step by step" trick works decently well for zero-shot prompting:
While these successes are often attributed to LLMs' ability for few-shot learning, we show that LLMs are decent zero-shot reasoners by simply adding "Let's think step by step" before each answer.
Zero-shot prompting refers to when a model is making predictions without any additional training or examples of how to perform a particular task.
As OpenAI highlights, the authors of this paper found the Let's think step-by-step works well for certain tasks, but not all:
The authors found that it was most helpful for multi-step arithmetic problems, symbolic reasoning problems, strategy problems, and other reasoning problems. It didn't help with simple math problems or common sense questions, and presumably wouldn't help with many other non-reasoning tasks either.
Aside from the generic Let's think step-by-step, OpenAI suggests trying more structured, specific instructions to get the model to reason for the task at hand, for example First, think step by step about why X might be true. Second, think step by step about why Y might be true. Third, think step by step about whether X or Y makes more sense..
Few shot prompting
Next up, let's look at a powerful technique for improving GPT-3 and GPT-4 responses: few shot prompting.
Few shot prompting involves providing a few examples of the desired output, or examples of "chain of thought" reasoning. For example, in Google's paper called Language Models Perform Reasoning via Chain of Thought they highlight:
Called chain of thought prompting, this method enables models to decompose multi-step problems into intermediate steps. With chain of thought prompting, language models of sufficient scale (~100B parameters) can solve complex reasoning problems that are not solvable with standard prompting methods.
As the authors highlight, providing "few shot" examples of chain-of-thought reasoning allows models to split complex problems into simpler steps that are then solved individually.
GPT-3 fine-tuning to improve performance
Lastly, in order to really improve model performance and improve reliability, OpenAI writes that fine-tuning a custom model is the way to go.
In general, to eke out maximum performance on a task, you'll need to fine-tune a custom model. However, fine-tuning a model using explanations may take thousands of example explanations, which are costly to write.
As they mention, however, fine-tuning can be costly so it's best to start with zero and few shot prompting first.
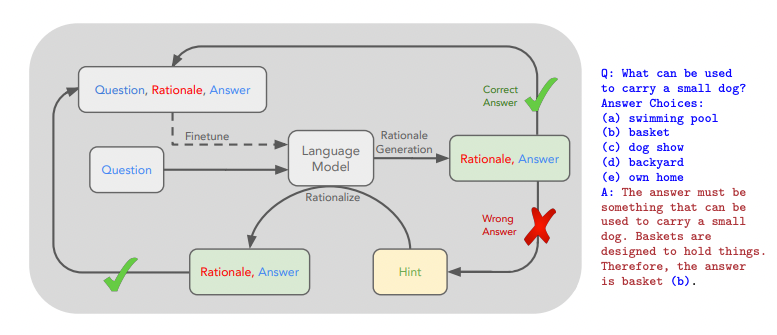
The notebook provides an interesting paper that presents an alternative to the time-consuming process of writing your own fine-tuning examples: STaR: Bootstrapping Reasoning With Reasoning.
As the authors write:
We propose a technique to iteratively leverage a small number of rationale examples and a large dataset without rationales, to bootstrap the ability to perform successively more complex reasoning. This technique, the "Self-Taught Reasoner" (STaR), relies on a simple loop: generate rationales to answer many questions, prompted with a few rationale examples; if the generated answers are wrong, try again to generate a rationale given the correct answer; fine-tune on all the rationales that ultimately yielded correct answers; repeat.
In other words, using the approach you get both the benefits of fine-tuning and chain-of-thought prompting without having to go through the costly and time-consuming process of writing all the fine-tuning examples yourself.
Very cool.
We'll do a full post on chain-of-thought prompting as there are many more techniques to improve results, but for now, you can check out a few others in OpenAI's Cookbook.
Summary: Improving large language model (LLM) performance with prompt engineering
As you can guess, there's been a signification amount of research going into the field of prompt engineering and improving the performance of LLMs over the past 12 months.
As the pace of language model performance continues to accelerate, there's no question that some of these techniques won't be needed (i.e. simply using GPT-4 may solve many of the previous reasoning issues).
That said, understanding these foundational principles and prompt engineering techniques will undoubtedly be a valuable part of any machine learning engineer or AI enthusiast's toolkit, at least for a few years.
I started as a prompt engineer at OpenAI in 2020. With ChatGPT & GPT-4, so much has changed.
— Andrew Mayne (@AndrewMayne) March 16, 2023
We’re now in the next phase. The term “prompt engineer” is feeling as antiquated as “typist” or “computer operator.”
We’re all prompt engineers now.




