

In our previous guide on getting stated with AutoGPT we saw how to install and start experimenting with this exciting new project.
In this guide, we'll expand on that and see how we can add long-term memory to our autonomous AI agents with Pinecone. In case you're unfamiliar...
Auto-GPT is an experimental open-source application showcasing the capabilities of the GPT-4 language model. This program, driven by GPT-4, chains together LLM "thoughts", to autonomously achieve whatever goal you set. As one of the first examples of GPT-4 running fully autonomously, Auto-GPT pushes the boundaries of what is possible with AI.
In order to add long-term memory to AutoGPT, the steps we need to take include:
- Step 1: Install & configure AutoGPT
- Step 2: Pinecone API Key Setup
- Step 3: Running AutoGPT with Pinecone
- Step 4: Ingesting data with memory pre-seeding
**Note that as this Github issue highlights, Pinecone & AutoGPT should be used with extreme caution as (at the time of writing), Pinecone no longer offers a free plan and AutoGPT leaves the Pinecone index service running unless you terminate it manually, meaning you will be charged for these cloud resources.
In most cases, using local storage will be sufficient for personal use, Pinecone and other cloud-based vector databases are really only needed if you plan to build a more production-level autonomous AI assistant.
With that all being said, let's dive into how to set up long term memory with AutoGPT and Pinecone for those that are interested.
 Peter Foy
Peter Foy
Step 1: Install & configure AutoGPT
In case you haven't already installed & configured AutoGPT, here are the quickstart steps you'll need to take before setting up long term memory:
- Clone GitHub repo with
git clone https://github.com/Significant-Gravitas/Auto-GPT.gitandcd Auto-GPT - Install the dependences with
pip install -r requirements.txt - Create a copy of the .env.template file with
cp .env.template .env - Navigate to the new
.envfile and set your OpenAI API key here:OPENAI_API_KEY=
Step 2: Pinecone API Key Setup
Alright, next up let's go and setup long term memory with Pinecone. In case you're unfamiliar, Pinecone is a vector database that enables long-term memory for AI. As they highlight in their article on vector databases:
Vector databases are purpose-built to handle the unique structure of vector embeddings. They index vectors for easy search and retrieval by comparing values and finding those that are most similar to one another.
In other words, Pinecone provides the ability to store and retrieve vast quantities of vector-based memory. In the context of AutoGPT, this means the agent can store and retrieve relevant information related to the role or goals you set.
Before adding Pinecone to AutoGPT, you'll just need to:
- Setup an a Pinecone account here
- You can choose the Starter plan to avoid being charged, otherwise AutoGPT using Pinecone will cost you money so keep that in mind
- Navigate to the API keys section to find your environment and API key values
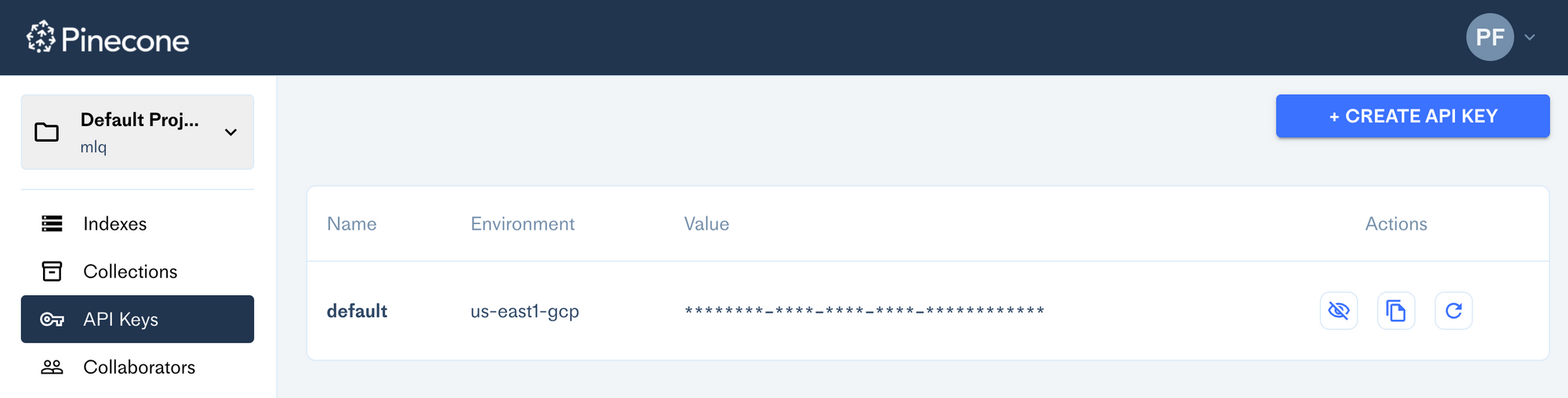
Next, head back to your .env file in AutoGPT and make the following changes:
- Set your
PINECONE_API_KEYwith no brackets or spaces - Do the same with your
PINECONE_ENVkey (i.e.us-east1-gcp) - Set the
MEMORY_BACKEND=pinecone, by defualt it will use your local memory
Step 3: Running AutoGPT with Pinecone
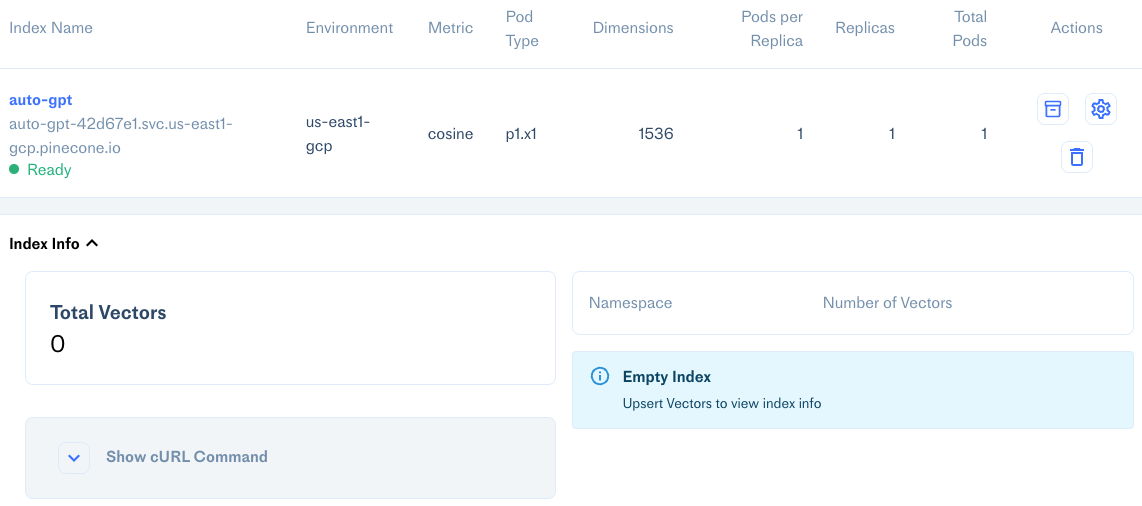
Now, when we run AutoGPT with python -m autogpt we can see this new empty index is setup in our Pinecone console:
For this example, I'm going to create an assistant to research trending machine learning papers and then write summaries and be able to answer questions about them, which I'll call AcademicGPT and set the role as...
...an AI designed to research trending machine learning papers and then write summaries and answer questions about them.
For the goals, I'll add:
- Research trending academic papers in AI and machine learning
- Either choose a paper or use the user's input and read the paper into memory
- Write a summary and answer questions of the paper
- Output the result in markdown format
After running this, I can see it wants to use the paper on Compute Trends Across Three Eras of Machine Learning. After using the browse_website command and reading the paper, I can also see my Total Vector count going up in Pinecone.
After a few iterations, here we have our AutoGPT summary of the paper:
The paper titled 'Compute Trends Across Three Eras of Machine Learning' by Jaime Sevilla and 4 other authors discusses trends in the most readily quantified factor - compute, and how it has grown in line with Moore's law before 2010, doubling roughly every 20 months. Since the advent of Deep Learning in the early 2010s, the scaling of training compute has accelerated, doubling approximately every 6 months. In late 2015, a new trend emerged as firms developed large-scale ML models with 10 to 100-fold larger requirements in training compute. Based on these observations, the history of compute in ML is split into three eras: the Pre Deep Learning Era, the Deep Learning Era, and the Large-Scale Era. Overall, the paper highlights the fast-growing compute requirements for training advanced ML systems.
Not bad.
Step 4: Ingesting data with memory pre-seeding
Next, let's let's look at how to pre-seed our memory backend with other files. As the AutoGPT Github highlights:
Memory pre-seeding allows you to ingest files into memory and pre-seed it before running Auto-GPT.
Memory pre-seeding is a technique for improving AI accuracy by ingesting relevant data into its memory.
In order to ingest data into AutoGPT, I'm first going to create a new folder called DataFolder within the auto_gpt_workspace folder. For this example, I'm going to add the Attention is All You Need paper (of course), to my DataFolder.
It looks like at the moment AutoGPT can't actually parse PDFs at the moment, so we'll either need to use LangChain or any other PDF to text tool to convert our text.
For this example I'll just use a simple PDF to text tool, although we can also do with this code as highlighted in this article Building a GPT-3 Enabled Research Assistant with LangChain & Pinecone.
Ok now that I've got my .txt file in the DataFolder, next up, let's go and ingest this files into memory with with data_ingestion.py script:
# python data_ingestion.py -h
usage: data_ingestion.py [-h] (--file FILE | --dir DIR) [--init] [--overlap OVERLAP] [--max_length MAX_LENGTH]
Ingest a file or a directory with multiple files into memory. Make sure to set your .env before running this script.
options:
-h, --help show this help message and exit
--file FILE The file to ingest.
--dir DIR The directory containing the files to ingest.
--init Init the memory and wipe its content (default: False)
--overlap OVERLAP The overlap size between chunks when ingesting files (default: 200)
--max_length MAX_LENGTH The max_length of each chunk when ingesting files (default: 4000)For example, I'll use the the following parameters:
maximum_lengthof 2000overlapof 100
As the Github highlights, we can fine tune these parameters to control how the documents are presented to AutGPT when it"recalls" that memory.
- Increasing the overlap values allows the AI to access more contextual information when reading each chunk, although it will also increase the number of chunks and thus the memory backed used
- We can also increase the
max_lengthto reduce the number of chunks, although this will increase the overall tokens you're sending with each OpenAI API call - Reducing
max_lengthwill create more chunks but will also save on prompt token costs
To run this and ingest this paper into Pinecone memory, I'll need to run the following command:
python data_ingestion.py --dir DataFolder --init --overlap 100 --max_length 2000
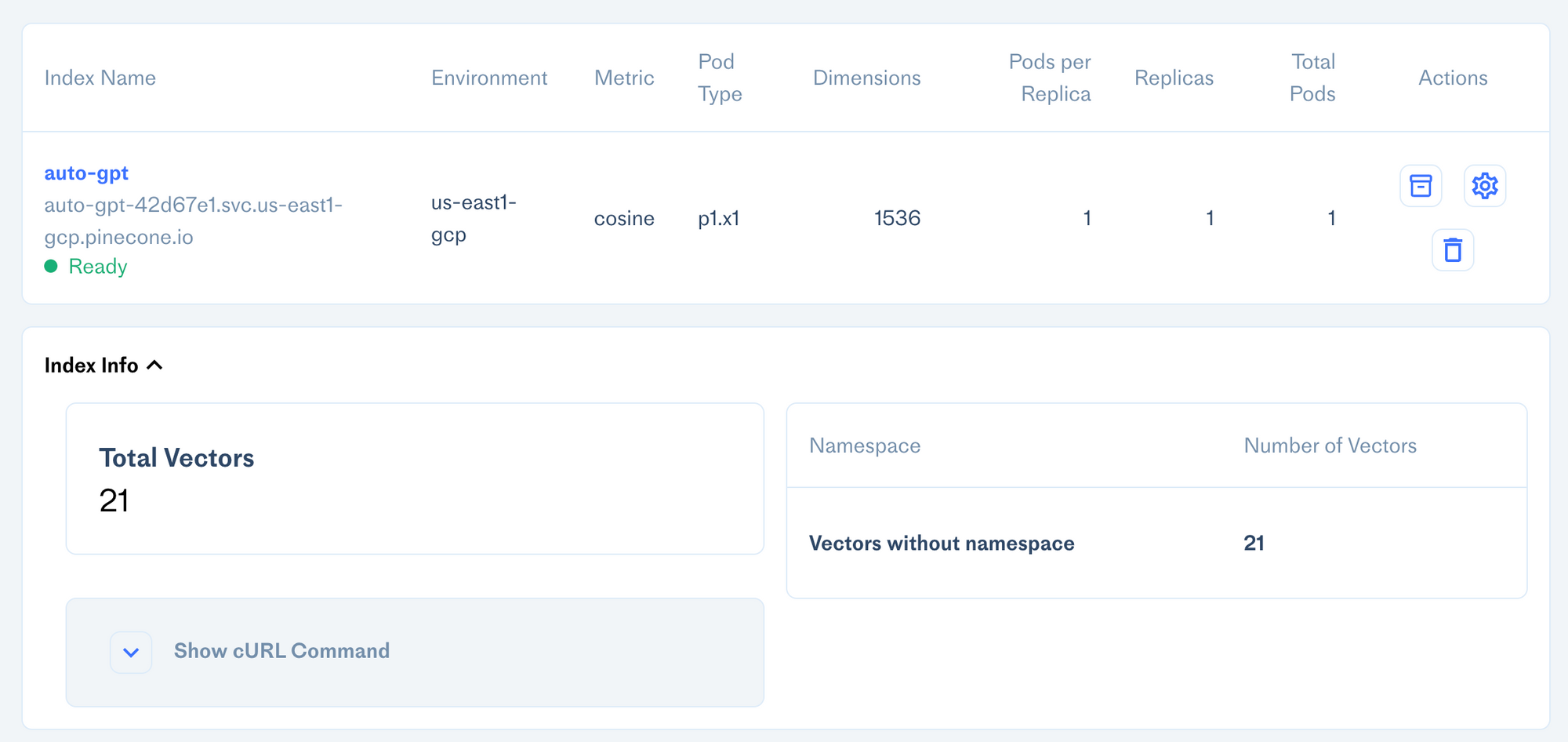
Now that we've ingested the paper into memory, we can see the total vectors of the index has gone up to 21:
Summary: Adding Long Term Memory to AutoGPT
While it's been interesting to experiment with long term memory, as I mentioned for the vast majority of personal use cases, local cache should do just fine.
I also found that AutoGPT wouldn't always retrieve information from Pinecone even with specific instruction, and instead opt to use Google and re-read papers that it already had in memory.
As always, it's important to remember that as the name suggests AutoGPT is very experimental at this stage and won't always work as intended.
That said, it sure is fun to play around with and it's becoming quite clear that autonomous agents are going to play a big role in AI in the coming years...
AutoGPT just exceeded PyTorch itself in GitHub stars (74k vs 65k). I see AutoGPT as a fun experiment, as the authors point out too. But nothing more. Prototypes are not meant to be production-ready. Don't let media fool you - most of the "cool demos" are heavily cherry-picked: 🧵 pic.twitter.com/I44H7BkCqr
— Jim Fan (@DrJimFan) April 16, 2023



