For many use cases working work LLMs, you'll want to incorporate external knowledge or data in order to customize the responses to a specific task.
This process of augmenting LLMs with external information that the model isn't previously trained on is called Retrieval Augmented Generation, or RAG.
In this guide, we'll discuss what RAG is, including key concepts, terms, and use cases:
- What is RAG?
- RAG: key concepts & terminology
- What are vector embeddings in RAG?
- What are vector databases?
- How embeddings & vector databases work together in RAG
Let's get started.
What is RAG?
Retrieval Augmented Generation, or RAG, is a technique used to enhance the performance of large language models (LLMs) by incorporating external knowledge from databases or other sources.
As we've discussed, LLMs have been trained on a massive amounts of data, although sometimes that general knowledge isn't sufficient for certain tasks.
RAG allows LLMs to update their existing knowledge in real-time with relevant and current information for a specific task. This "source knowledge" refers to the external data that's used to augment the LLMs existing capabilities.
If you've worked with ChatGPT before, for example, you've probably seen the it answer with something along the lines of "I'm sorry but my knowledge cutoff date with until April 2023...". RAG is one of the ways that you can mitigate this issue by retrieving current and contextual information related to the users question.
In short, by combining the capabilities of pre-trained language models with retrieval mechanisms, RAG can drastically improve the accuracy and quality of the LLMs response.
RAG: Key concepts & terminology
Now that we know what RAG is at a high level, let's review a few key concepts & terminology you'll need to know.
- Retrieval-Augmented Generation (RAG): A methodology for integrating a retrieval component with a pre-trained generative language model. The retrieval component searches a large corpus of documents or data to find relevant information, appends that information onto the user's query, which the language model uses to generate responses.
- Knowledge Base: The collection of documents or a data that the RAG model queries to retrieve information. This could include a set of research papers, Wikipedia articles, or any large-scale dataset relevant to the task at hand.
- Embeddings: High-dimensional vectors that represent the semantic meaning of texts, such as queries, documents, or passages, in a continuous vector space.
- Vector Database: Vector databases, or vector search engines, are specialized databases designed to efficiently store and query high-dimensional vector data.
- Dense Passage Retrieval (DPR): A common retrieval mechanism used in RAG models to efficiently find relevant documents from a large corpus. DPR uses dense vector embeddings of the query and documents in the corpus to perform similarity matching.
The concept of embeddings and vector database are quite crucial in RAG, so let's dive into these in a bit more detail.
What are vector embeddings in RAG?
Embeddings are a key concept in RAG that allow you to bridge the gap between vast amounts of unstructured data from the knowledge base and the need to precise, contextually relevant retrieval based on the users query.
Embeddings transform words, sentences, or entire documents into high-dimensional vectors.
These vectors are able to capture the semantic meaning of text, enabling the system to understand the nuances of natural language on a much deeper level than simple keyword matching.
In order to understand and visualize vector embeddings, you can check out TensorFlow's embedding projector tool, which as they highlight:
The TensorBoard Projector is a great tool for interpreting and visualzing embedding. The dashboard allows users to search for specific terms, and highlights words that are adjacent to each other in the embedding (low-dimensional) space.
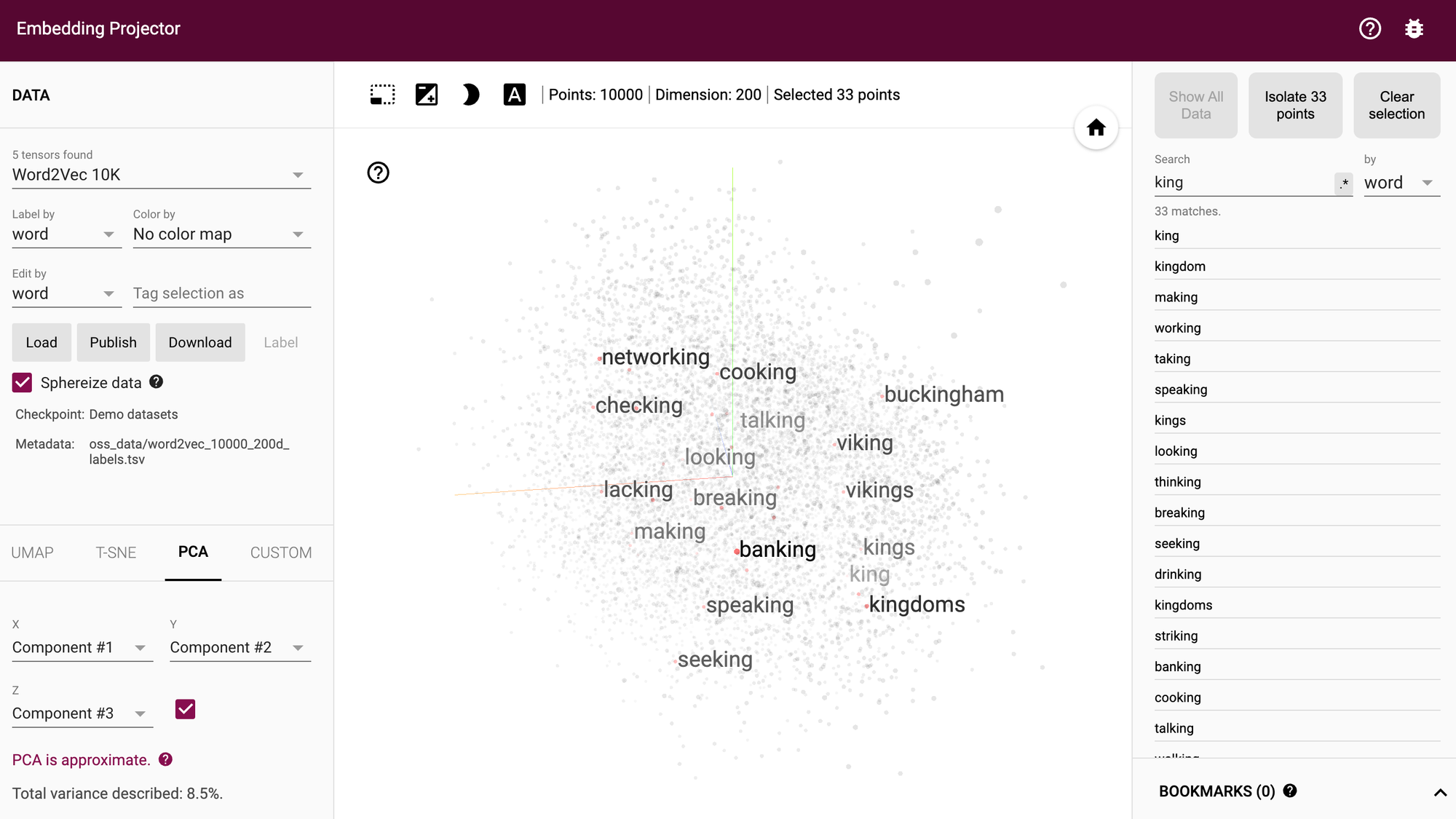
In the context of RAG, transforming raw text into vector embeddings allows the model to understanding the relevance and context of certain texts, even if there is no explicit keyword overlap.
In other words, this allows the model to search for semantically similar text that has closely aligned vectors in high-dimensional space that is conceptually relevant to the users' query.
What are vector databases?
After you've transformed your text into vector embeddings, we then want to store them somewhere so we can efficiently query and retrieve the information. This is where vector databases come in.
A vector database, or vector search engine, are specialized storage and retrieval systems designed to work with this high-dimensional vector data produced by the embedding model.
In the context of RAG, the vector database plays a crucial role in enabling the retrieval component to operate with high efficiency and accuracy.
As the vector database startup Pinecone writes:
Efficient data processing has become more crucial than ever for applications that involve large language models, generative AI, and semantic search.
With a vector database, we can add knowledge to our AIs, like semantic information retrieval, long-term memory, and more.
How embeddings & vector databases work together in RAG
Now, to understand these concepts, let's walk through a step by step example of how RAG works.
Step 1: Transform the users' query into embeddings
When a user sends a query into an RAG-enabled LLM, we first need to transform the input text into vector embeddings. The goal is to have both our query and knowledge base in the same vector embedding format, leading us to step 2...
Step 2: Vector database search
Next, with the user's query in vector format we can then search through potentially millions of vectors stored in our database.
The search tries to find vectors that are semantically similar to the query vector, based on metrics like cosine similarity or Euclidean distance. This step is critical, as it determines which pieces of information from the knowledge base are most relevant to the user's query.
In other words, we're able to efficiently search through our entire knowledge base and find contextually relevant information.
Step 3: Retrieving contextually relevant information
After we've searched the vector database, it will return a list of documents or text that are considered semantically similar to the users query, meaning it likely contains relevant information.
In this step, we often return a set number of relevant document sections in order to answer the user's question, leading us to step 4.
Step 4: Sending relevant information to the LLM
Now with the retrieved documents as well as the original users query, we can feed these two into an LLM in order to sythesize and prepare a response. For example, if the user asks a very specific question about a document, and the vector database found 5 relevant sections, the goal of this step is to feed all the information into an LLM and have it discern which sections are relevant to answer the question.
Step 5: Delivering the response
Finally, we're now ready to answer the users' question. Now the response has been enriched with relevant information from our external knowledge base (i.e. our vector database).
In summary, by combining the properties of embeddings, vector databases, and generative language models, RAG-enabled systems are able to drastically enhance the quality and depth of their responses.
Use cases of RAG
Now that we know how RAG works through the process of embeddings, vector databases, retrieval, and generative AI, let's discuss a few use cases:
- Questing answering: Answering specific questions based on external knowledge is a very common use case. This could be for answering questions based on a company's internal documentation, a set or documents, and so on.
- Content creation: Another way to enhance the quality of AI-assisted content creation is by adding an RAG component. For example, you could enhance an LLM with examples or writing style or with related content to speed up your writing process.
- Chatbots: RAG is also useful for general purpose chatbots, for example if you want to enhanced the pre-trained model with up-to-date information such as stock market data, recent news, and so on.
- Research assistants: Finally, a common use case for RAG is in assistant research as it enables you to summarize relevant literature, answer questions based on certain papers, and so on.
Summary: Intro to RAG
In summary, Retrieval-Augmented Generation is one of the best ways to enhance the capabilities of a pre-trained LLM like GPT-4.
By combining the strengths of embeddings, vector databases, retrieval mechanisms, and LLMs, RAG opens up a range of new possibilities for generative AI.
From business-specific information to academic research, RAG plays a key role in making AI-generated responses more accurate and contextually relevant for the task at hand.