In our previous articles on GPT 3.5 fine tuning, we've how to fine tune GPT 3.5 for tasks like creating a consistent brand voice. In this guide, we'll look at another key use case of fine tuning: structured ouptut formating.
Specifically, we'll look at how we can fine tune GPT 3.5 in order to parse finanancial news headlines into structured data.
In case you're unfamiliar with fine tuning, as OpenAI puts it:
Fine-tuning improves on few-shot learning by training on many more examples than can fit in the prompt, letting you achieve better results on a wide number of tasks.
In other words, we're "retraining" the pre-trained 3.5 turbo model in order to tailor the model to our own specific use case.
To do so, we'll take the following steps:
- Step 1: Identify the desired structured output
- Step 2: Fill in prompt template
- Step 3: Create a fine-tuning dataset
- Step 4: Create a fine tuning job
- Step 5: Test the fine tuned model
Let's get started.
 Peter Foy
Peter Foy
Step 1: Identify the Desired Structured Output
Alright step 1 we need to decide on the structured ouput that we want from each input.
Here's a (fictional) example of how we can fine tune GPT 3.5 for structured ouput:
Input: Apple Inc. stocks soared by 5% after announcing its new iPhone on September 1, 2023.
Output: {"stock_symbol": "AAPL", "price_change": "5%", "event": "new iPhone announcement", "date": "September 1, 2023"}
As you can see, we're extracting key pieces of information from the headline, including:
- Stock Symbol
- Price Change
- Event
- Date
Step 2: Structured Output Prompt Template
Now that we know what output we want from each input, we've created a prompt template that will help you create fine tuning datasets based on your requirement.
This prompt template aims to guide you through the process of creating a fine-tuning dataset. First, we'll review the guidelines of each "role" we'll need in the training dataset. By answering the qeustions in each section, you'll nd then answer several questions to create the dataset.
System Role
Each interaction begins with a message from the 'system' role, which sets the context for the assistant.
Example: "You are a fine-tuned model trained to extract structured financial information."
User Role
The user role is a message containing the information that needs to be extracted into our desired structured output.
Example: "Apple Inc. stocks soared by 5% after announcing its new iPhone on September 1, 2023."
Assistant Role
The assistant role provides training examples of the desired output. In the case of structured output fine tuning, this will contain the extracted structured information in JSON-like format.
Example: {"stock_symbol": "AAPL", "price_change": "5%", "event": "new iPhone announcement", "date": "September 1, 2023"}
Sample Dataset Entry
Here's a simple format you can follow for creating your fine tuning dataset for structured outputs:
{
"messages": [
{"role": "system", "content": "Your context-setting message here"},
{"role": "user", "content": "Your user-provided information here"},
{"role": "assistant", "content": "Your structured output in JSON-like format here"}
]
}Step 3: Create a Fine-Tuning Dataset
Alright after we've answered the questions above and have a few examples of our ideal input/outputs, we can simply copy those into ChatGPT in order to generate 50+ examples.
As OpenAI highlights:
To fine-tune a model, you are required to provide at least 10 examples. We typically see clear improvements from fine-tuning on 50 to 100 training examples.
Each training example will look something like this:
{
"messages": [
{"role": "system", "content": "You are a fine-tuned model trained to extract structured financial information."},
{"role": "user", "content": "Apple Inc. stocks soared by 5% after announcing its new iPhone on September 1, 2023."},
{"role": "assistant", "content": "{\"stock_symbol\": \"AAPL\", \"price_change\": \"5%\", \"event\": \"new iPhone announcement\", \"date\": \"September 1, 2023\"}"}
]
}
With this dataset created, all we need to do is save it in JSONL format and we're ready to start the fine tuning process.
We can also optionally run the dataset through the data formatting script OpenAI provides, which will return something like this if it's formatted correctly:
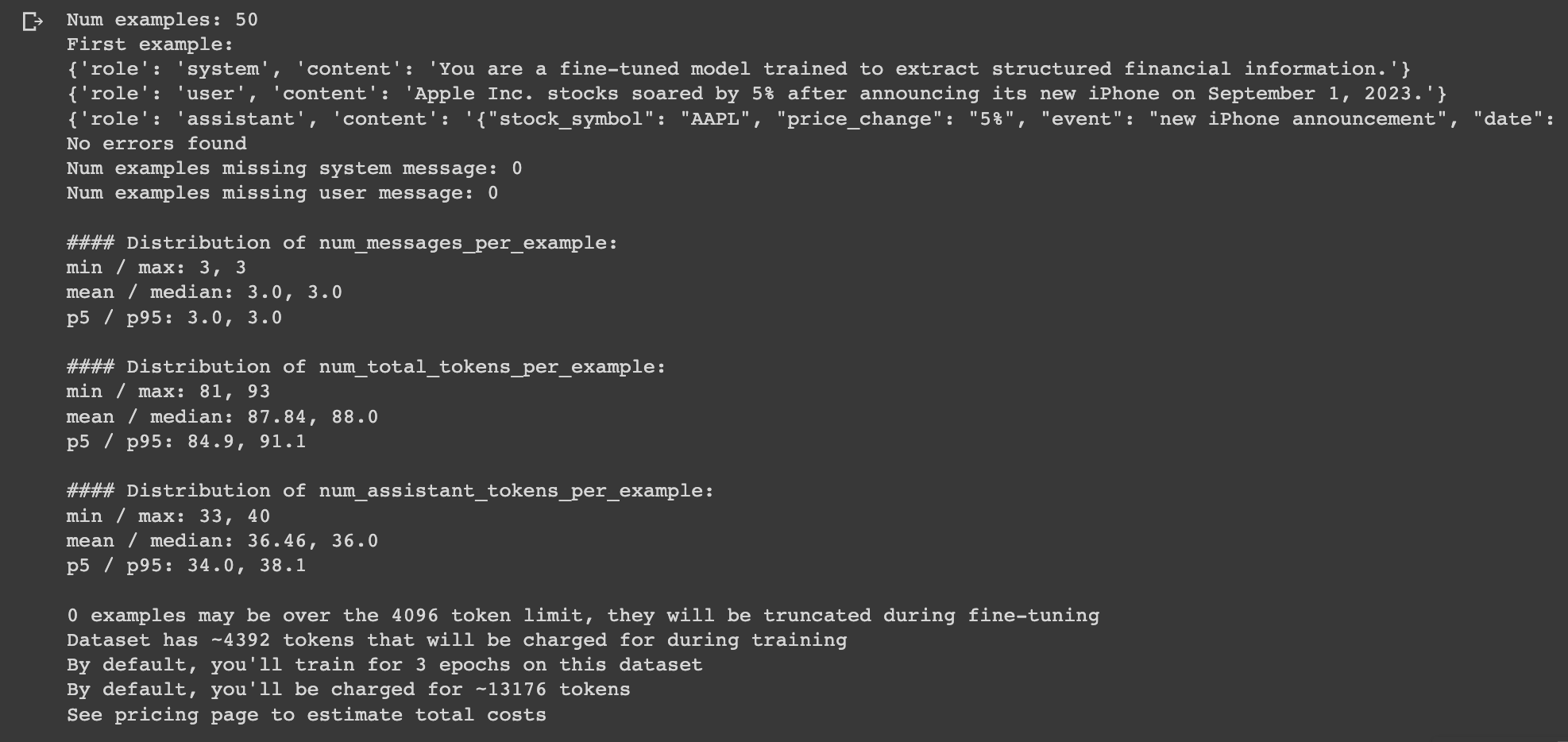
Step 4: Fine-Tuning the GPT-3.5 Model
With our training dataset, the next step is to upload the file to OpenAI for fine tuning, which we can do as follows:
import openai
# Upload the file first
openai.File.create(
file=open("/path/to/your_file.jsonl", "rb"),
purpose='fine-tune'
)
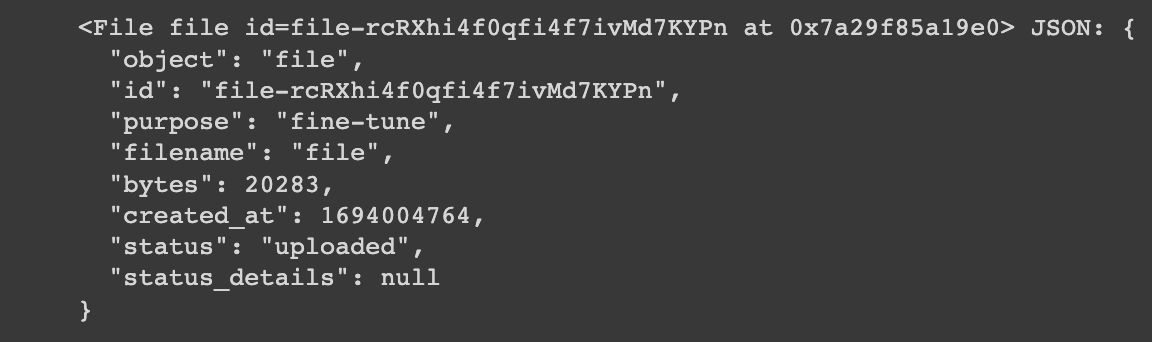
Next, we're ready to create the fine-tuning job as follows:
# Create the fine-tuning job
openai.FineTuningJob.create(training_file="file-abc123", model="gpt-3.5-turbo")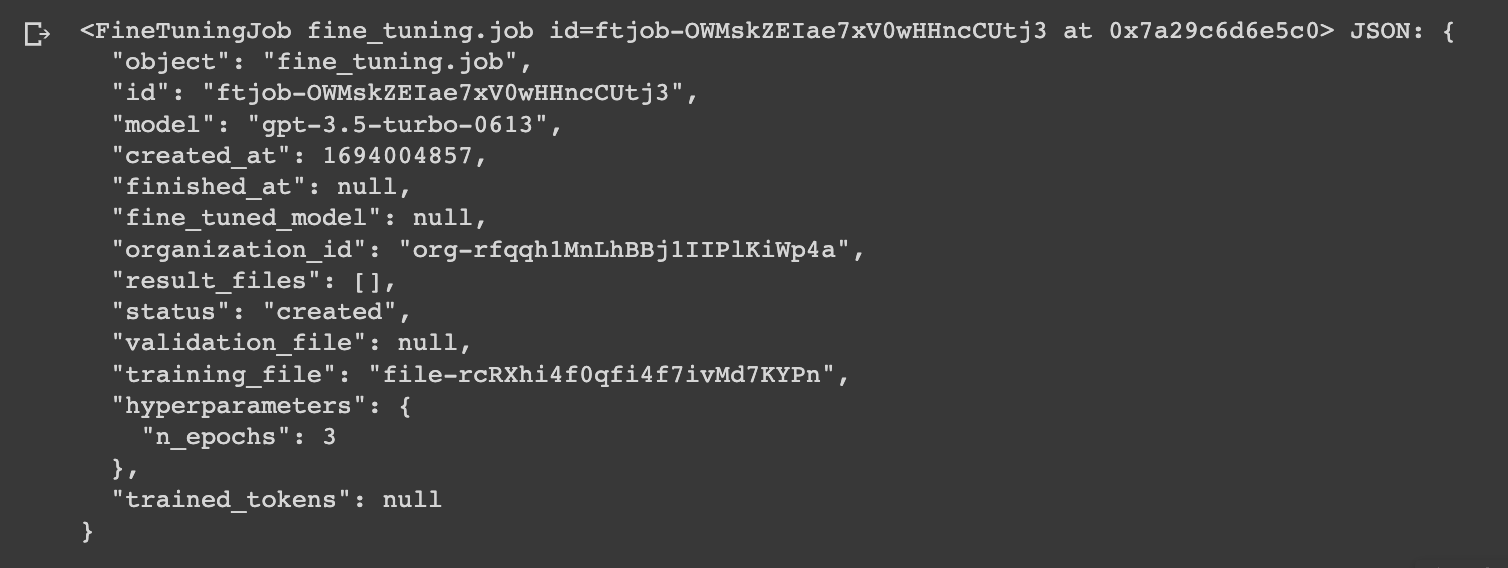
After creating the fine tuning job, we can check the status of it with the ftjob-id just created:
openai.FineTuningJob.retrieve("your-ftjob-id")
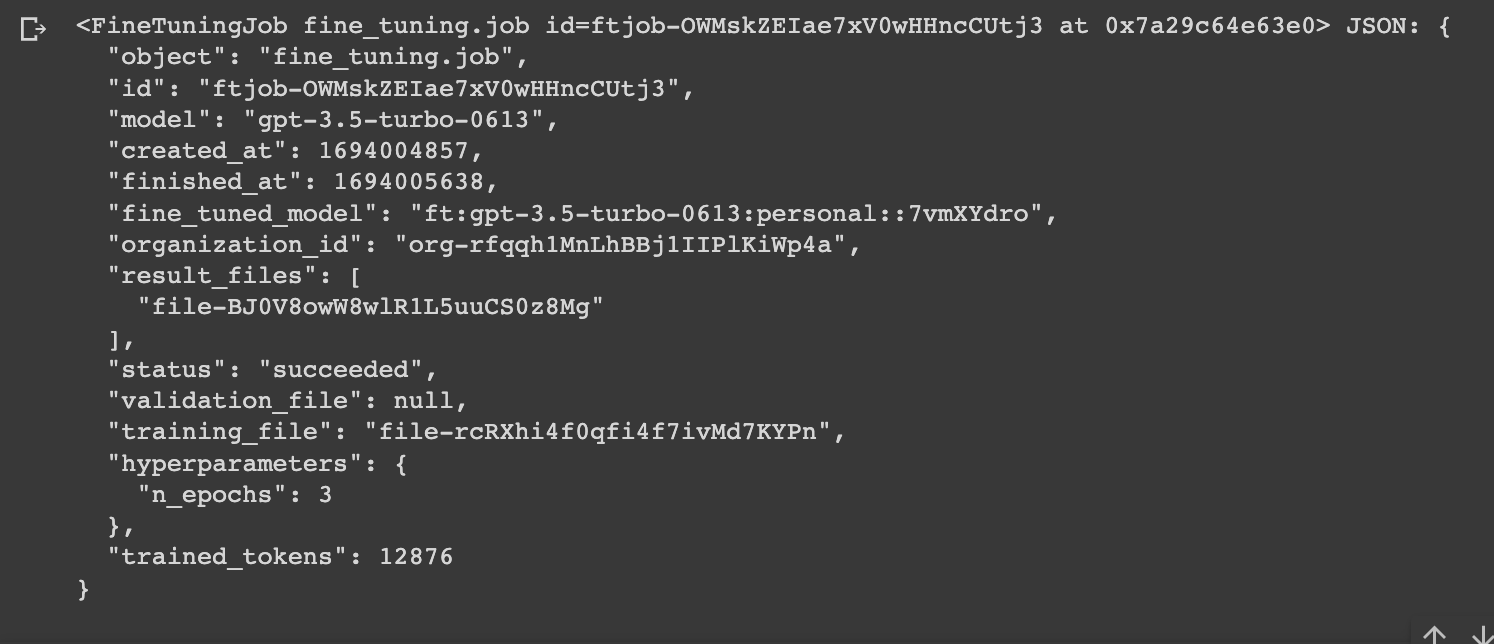
Step 4: Testing the Fine Tuned Model
Once the fine tuning job is complete, the real question is whether we see a notable difference from the base model. To test this, let's use the same system and user message for both the fine tuned and base model:
Fine tuned model
# Test with fine-tuned model
completion = openai.ChatCompletion.create(
model="your-fine-tuned-model-id",
messages=[
{"role": "system", "content": "You are trained to extract structured financial information."},
{"role": "user", "content": "Microsoft stocks jump 4.5% following the release of a breakthrough cloud computing technology on November 15, 2023.
]
)
print(completion.choices[0].message['content']){
"role": "assistant",
"content": "{\"stock_symbol\": \"MSFT\", \"price_change\": \"4.5%\", \"event\": \"release of a breakthrough cloud computing technology\", \"date\": \"November 15, 2023\"}"
}Looking good! We can see we've got the correct output format.
Base model
# Test with base model
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are trained to extract structured financial information."},
{"role": "user", "content": "Microsoft stocks jump 4.5% following the release of a breakthrough cloud computing technology on November 15, 2023."}
]
)
print(completion.choices[0].message['content'])
{
"role": "assistant",
"content": "It is not possible for me to provide real-time information as I am a language model trained on data up until September 2021. Therefore, I cannot provide the latest information on Microsoft stocks. I recommend checking a reliable financial news source or contacting a financial advisor for the most up-to-date information on stock prices."
}As you can see, without any training examples the base model responds with the classic (rather annoying) GPT training cutoff response...
Of course, we could try get closer to the fine tuned model by providing more examples of ideal outputs in the system message, but that would increase our token usage for each additional user query, i.e. increasing overall API costs.
Summary: Fine Tuning GPT 3.5 for Structured Output
As we've seen, with a bit of data preparation and just a few lines of code we can fine tune GPT to provide structured output in our ideal output format.
In summary, instead of constantly having the re-prompt GPT or use the system message to provide training examples (and increase our token usage), we can use fine tuning to improve performance, decrease API costs, and reliably output content in our desired format.