

In this GPT-3 guide, we're going to look at how to make recommendations using the OpenAI Embeddings API and nearest neighbor search.
Recommendation engines are one of the most widespread applications of machine learning on the web today, and include everything from recommending similar products on Amazon, shows to watch on Netflix, recommending similar articles on media sites, and so on.
In our previous articles on GPT-3 we focused on training the base model on an additional body of knowledge so it could answer factual questions.
In this guide, we'll go through OpenAI's notebook on recommendations using embeddings to understand how to use embeddings to recommend similar news articles using AG's corpus of news articles as the dataset.
Embeddings are numerical representations of concepts converted to number sequences, which make it easy for computers to understand the relationships between those concepts.
In particular, we'll use embeddings to answer the question: given an article, what other articles are the most similar?
To answer this question, we'll take the following steps:
- Imports
- Load the data
- Save embeddings for reuse
- Making recommendations using embeddings
- Example recommendations
- Visualizing article embeddings
Also, if you want to see how you can use the Embeddings & Completions API to build simple web apps using Streamlit, check out our video tutorials below:
- MLQ Academy: Create a Custom Q&A Bot with GPT-3 & Embeddings
- MLQ Academy: PDF to Q&A Assistant using Embeddings & GPT-3
- MLQ Academy: Build a YouTube Video Assistant Using Whisper & GPT-3
- MLQ Academy: Build a GPT-3 Enabled Earnings Call Assistant
- MLQ Academy: Building a GPT-3 Enabled App with Streamlit
1. Imports
First, we'll start by pip installing OpenAI and importing the relevant packages we need:
# imports
import pandas as pd
import pickle
import openai
from typing import List, Dict, Tuple
openai.api_key = "YOUR-API-KEY"
from openai.embeddings_utils import (
get_embedding,
distances_from_embeddings,
tsne_components_from_embeddings,
chart_from_components,
indices_of_nearest_neighbors_from_distances,
)Stay up to date with AI
2. Load the data
Next, we'll load in the dataset of news articles and look at a few examples.
# load data (full dataset available at http://groups.di.unipi.it/~gulli/AG_corpus_of_news_articles.html)
dataset_path = "https://cdn.openai.com/API/examples/data/AG_news_samples.csv"
df = pd.read_csv(dataset_path)
# print dataframe
n_examples = 5
df.head(n_examples)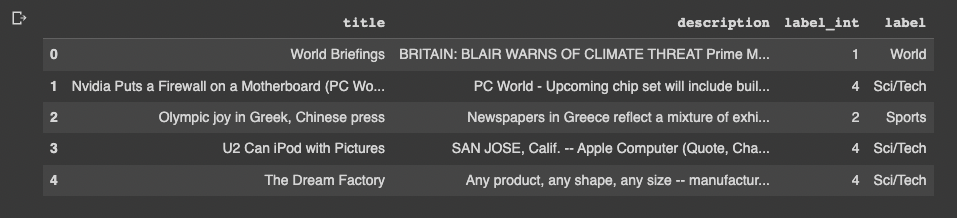
Here are a few examples of the full title, description, and labels:

3. Save embeddings for reuse
Next, let's create a cache so that we can save the embeddings we create so that we don't have to re-compute them each time.
In the code provided below from OpenAI, we're using a pre-filled cache to save and load the embeddings as a Python pickle fine. As the notebook highlights, "the cache is a dictionary that maps tuples of (text, engine) to a list of floats embedding":
# establish a cache of embeddings to avoid recomputing
# cache is a dict of tuples (text, engine) -> embedding, saved as a pickle file
# set path to embedding cache
embedding_cache_path_to_load = "example_embeddings_cache.pkl"
embedding_cache_path_to_save = "example_embeddings_cache.pkl"
# load the cache if it exists, and save a copy to disk
try:
embedding_cache = pd.read_pickle(embedding_cache_path_to_load)
except FileNotFoundError:
embedding_cache = {}
with open(embedding_cache_path_to_save, "wb") as embedding_cache_file:
pickle.dump(embedding_cache, embedding_cache_file)
# define a function to retrieve embeddings from the cache if present, and otherwise request via the API
def embedding_from_string(
string: str,
engine: str = "text-embedding-ada-002",
embedding_cache=embedding_cache
) -> list:
"""Return embedding of given string, using a cache to avoid recomputing."""
if (string, engine) not in embedding_cache.keys():
embedding_cache[(string, engine)] = get_embedding(string, engine)
with open(embedding_cache_path_to_save, "wb") as embedding_cache_file:
pickle.dump(embedding_cache, embedding_cache_file)
return embedding_cache[(string, engine)]Below we can confirm it's working by printing the first 10 dimensions of the first description in the dataset.

4. Making recommendations using embeddings
Now that we have our embeddings loaded, we can find similar articles by following these three steps:
- Retrieve the article description similarity embeddings for the whole dataset
- Compute the distance between the source title and other articles in the dataset
- Print out the most relevant articles to the source title
def print_recommendations_from_strings(
strings: List[str],
index_of_source_string: int,
k_nearest_neighbors: int = 1,
engine: str = "text-embedding-ada-002",
) -> List[int]:
"""Print out the k nearest neighbors of a given string."""
# get embeddings for all strings
embeddings = [embedding_from_string(string, engine=engine) for string in strings]
# get the embedding of the source string
query_embedding = embeddings[index_of_source_string]
# get distances between the source embedding and other embeddings (function from embeddings_utils.py)
distances = distances_from_embeddings(query_embedding, embeddings, distance_metric="cosine")
# get indices of nearest neighbors (function from embeddings_utils.py)
indices_of_nearest_neighbors = indices_of_nearest_neighbors_from_distances(distances)
# print out source string
query_string = strings[index_of_source_string]
print(f"Source string: {query_string}")
# print out its k nearest neighbors
k_counter = 0
for i in indices_of_nearest_neighbors:
# skip any strings that are identical matches to the starting string
if query_string == strings[i]:
continue
# stop after printing out k articles
if k_counter >= k_nearest_neighbors:
break
k_counter += 1
# print out the similar strings and their distances
print(
f"""
--- Recommendation #{k_counter} (nearest neighbor {k_counter} of {k_nearest_neighbors}) ---
String: {strings[i]}
Distance: {distances[i]:0.3f}"""
)
return indices_of_nearest_neighbors5. Example recommendations
Now let's use our print_recommendations_from_strings function to retrieve similar articles to the first one, which was about Tony Blair:
article_descriptions = df["description"].tolist()
tony_blair_articles = print_recommendations_from_strings(
strings=article_descriptions, # base similarity off of the article description
index_of_source_string=0, # look at articles similar to the first one about Tony Blair
k_nearest_neighbors=5, # look at the 5 most similar articles
)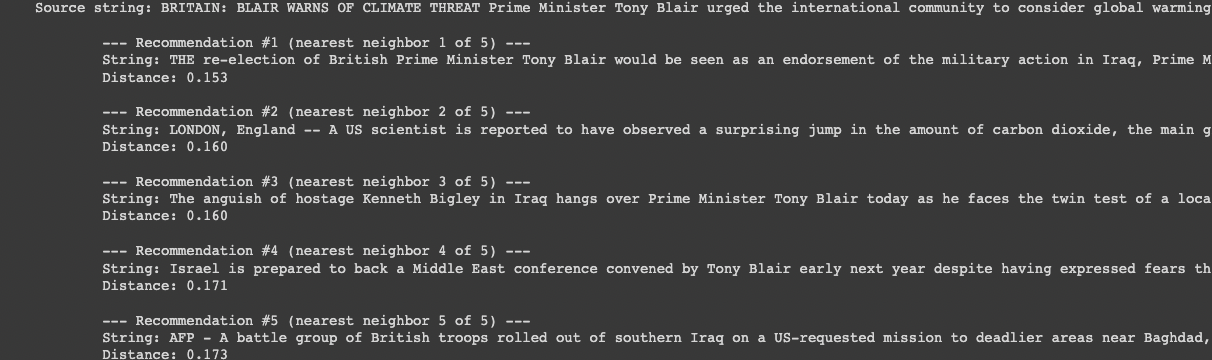
Nice! Right away we can see 4/5 articles explicitly mention Tony Blair, and the other one is an article about climate change which was also mentioned in the source article.
Let's try one more on the second article, which discusses NVIDIA's new chipset:
chipset_security_articles = print_recommendations_from_strings(
strings=article_descriptions, # let's base similarity off of the article description
index_of_source_string=1, # let's look at articles similar to the second one about a more secure chipset
k_nearest_neighbors=5, # let's look at the 5 most similar articles
)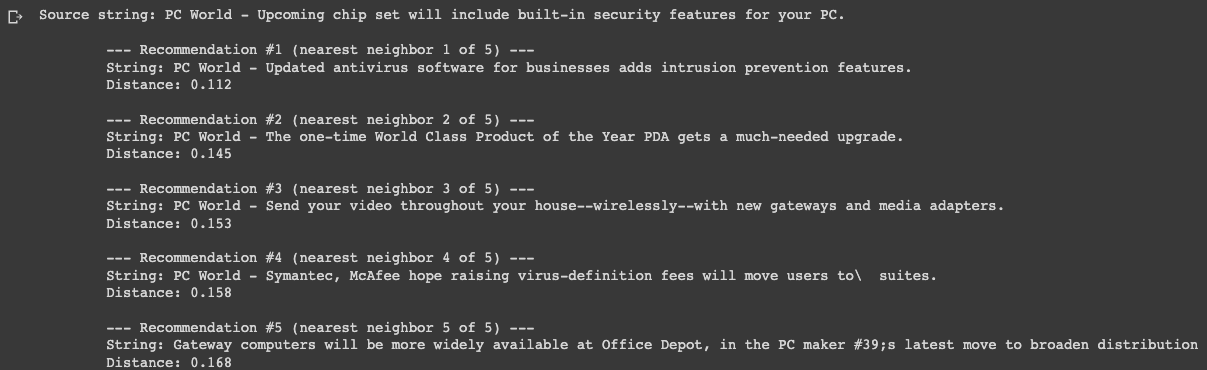
We can see from the printed distances that the first recommendation is closer than the others (0.11 distance vs. ~0.15). We can also see it's an article about antivirus software, so is related to the original article's topic on computer security.
6. Visualizing article embeddings
Before we conclude, let's visualize what this nearest neighbor recommender is actually doing by looking at the article embeddings.
Below, we'll visualize the t-SNE components of article descriptions, which is used to visualize high-dimensional data in a low-dimensional space. In particular, we're going to compress the 2048 dimensional embeddings into 2D with t-SNE:
# get embeddings for all article descriptions
embeddings = [embedding_from_string(string) for string in article_descriptions]
# compress the 2048-dimensional embeddings into 2 dimensions using t-SNE
tsne_components = tsne_components_from_embeddings(embeddings)
# get the article labels for coloring the chart
labels = df["label"].tolist()
chart_from_components(
components=tsne_components,
labels=labels,
strings=article_descriptions,
width=600,
height=500,
title="t-SNE components of article descriptions",
)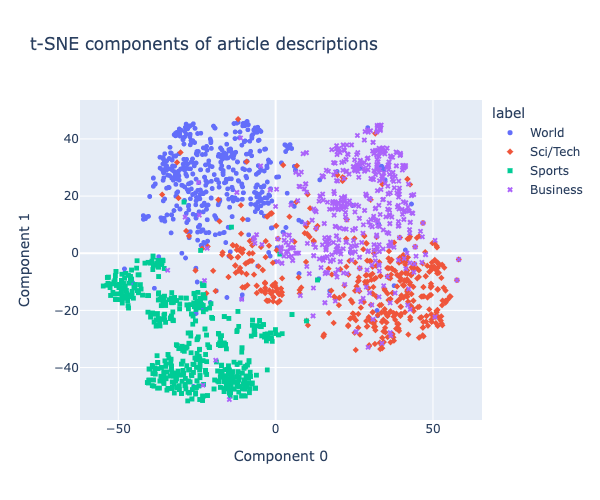
From this t-SNE visualization, we can see the compression embeddings are able to cluster article descriptions by category. It's worthwhile to note that this clustering is done without any knowledge of the labels...pretty cool.
Summary: Fine Tuning GPT-3 to Make Recommendations
In this guide, we discussed how you can fine tune GPT-3 with the OpenAI's Embeddings API and nearest neighbor search in order to build a recommendation engine.
Recommendations engines are one of the most widespread and valuable use cases of machine learning and are commonly applied to media sites for recommending similar articles, eCommerce sites for making product recommendations, and many others.
In this example, we used fine tunedGPT-3 to recommend similar news articles by using embeddings to map relationships between those articles.
To do so, we retrieved similarities for the article's description and then compared it against the whole dataset and computed the nearest f distance between these. Finally, we used the print_recommendations_from_strings to print out relevant article recommendations.




