

DeepSeek just dropped their new R1 model, and while NVIDIA and other AI chip stocks are taking a massive hit today due to concerns about compute requirements, there's a lot more to unpack here.
Let's dive deep into the paper to see what makes DeepSeek-R1 interesting, and why their approach to reinforcement learning might give us insights into the future of AI model training development.
DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrates remarkable reasoning capabilities.
Try Deepseek R1 Reasoning with Web Search
We've added Deepseek R1 reasoning to our AI research analyst. The model is hosted in US data centers, you can try if for free below:
The Zero-Shot Breakthrough: DeepSeek-R1-Zero
DeepSeek has managed something quite remarkable - building a powerful reasoning model without using any supervised fine-tuning data. While OpenAI and Anthropic typically start with supervised learning before moving to RL, DeepSeek took a different path by applying reinforcement learning directly to their base model.
The Pure RL Approach
Instead of following the traditional supervised learning → RL pipeline, DeepSeek went all-in on reinforcement learning from the start. They implemented Group Relative Policy Optimization (GRPO), an enhancement to Proximal Policy Optimization (PPO) that eliminates the need for a separate critic model.
Here's the key innovation: for each question, GRPO samples multiple outputs and uses the group's performance to estimate how well the model is doing. While traditional PPO needs a value function to estimate rewards, GRPO looks at the relative performance within each group of samples, making the training more efficient and stable.
The reward system they built is also remarkably simple:
- Accuracy rewards: Did the model get the right answer?
- Format rewards: Did it show its work between specific tags?
That's it. Instead of using neural reward models or complex process rewards, they achieved impressive results with just these two straightforward signals.
The "Aha Moment"
During training, the model developed some fascinating behaviors that it wasn't explicitly taught. The researchers observed the model would pause mid-solution with messages like "Wait, wait. That's an aha moment I can flag here" before backtracking, re-evaluating its approach, and often finding a better solution.

The results speak for themselves:
- On AIME 2024 (high school math olympiad problems), R1-Zero went from 15.6% to 71.0% accuracy, reaching 86.7% with consensus voting
- MATH-500 (college-level math problems) hit 95.9% accuracy
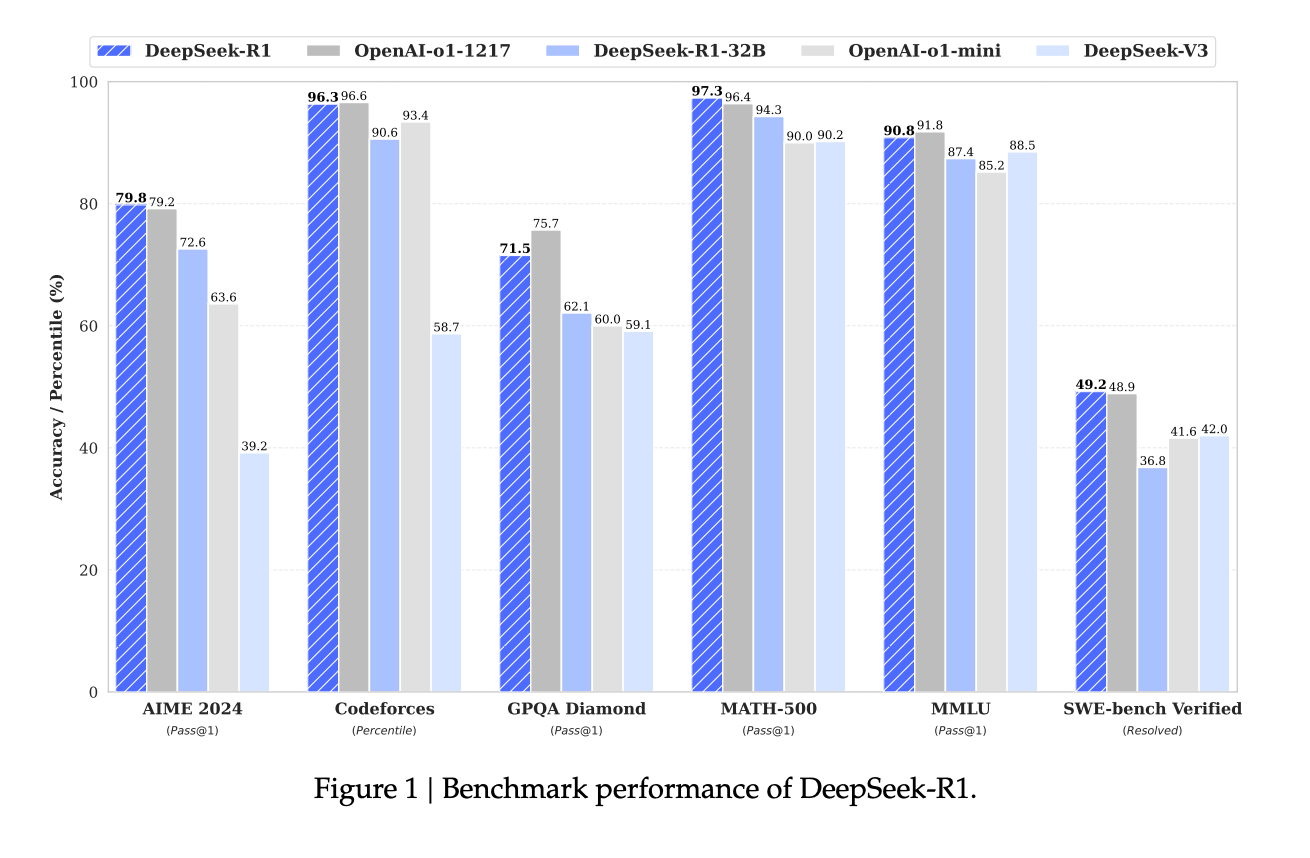
- The final DeepSeek-R1 model improved further: 79.8% on AIME and 97.3% on MATH-500, surpassing OpenAI's latest models
Looking at Figure 3 from the paper below, we see a clear evolution in how the model approaches problems. The average response length grows from around 1,000 tokens to nearly 10,000 tokens over 8,000 training steps. This wasn't hardcoded - the model learned on its own that more detailed reasoning led to better results.
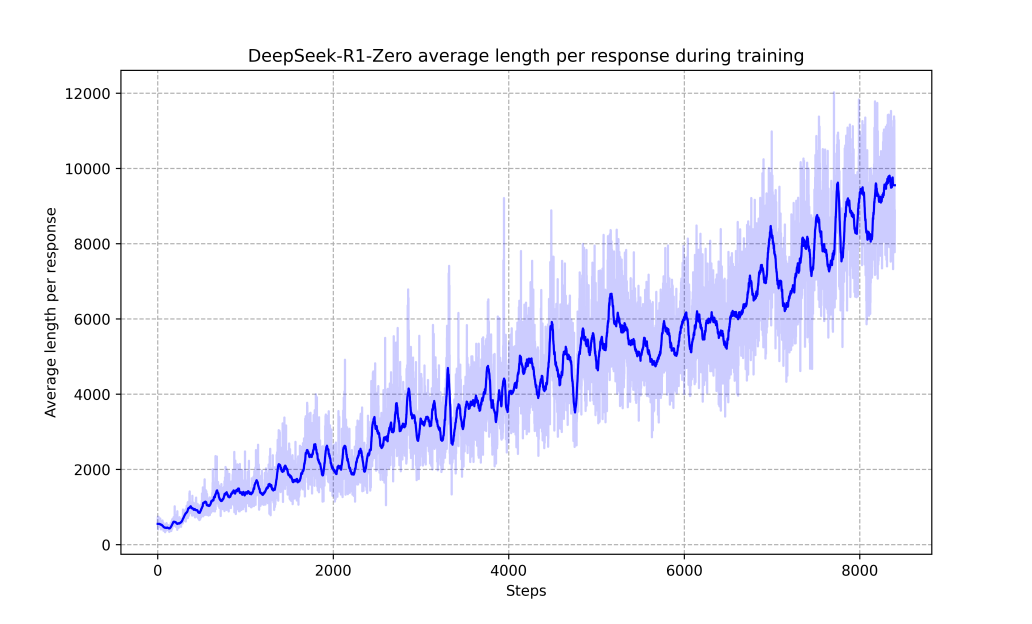
The notable thing here is that while most LLM training approaches optimize for shorter, more concise responses, DeepSeek-R1-Zero discovered independently that complex reasoning problems benefit from extended step-by-step thinking.
The Drawbacks
The pure RL approach did come with some challenges:
- Poor readability in outputs
- Language mixing (switching between languages mid-solution)
- Less controlled behavior compared to supervised approaches
These limitations led DeepSeek to develop their full R1 model, which we'll explore next. But the zero-shot breakthrough remains significant - it demonstrates that models can develop sophisticated reasoning capabilities through pure trial and error, without needing examples to follow.
The Evolution to DeepSeek-R1
While R1-Zero showed impressive results, its limitations prompted DeepSeek to develop a more refined approach. Instead of pure RL, they created a multi-stage pipeline that starts with a small amount of "cold-start" data before applying reinforcement learning.
The Cold Start Innovation
Unlike R1-Zero, the full R1 model begins with thousands of high-quality Chain-of-Thought (CoT) examples to fine-tune the base model. This data comes from multiple sources:
- Few-shot prompting with long CoT examples
- Direct prompting for detailed answers with reflection
- Curated outputs from R1-Zero
- Human-annotated refinements
This initial supervised phase gives the model a foundation in structured reasoning while maintaining readability - addressing one of R1-Zero's key limitations.
Multi-Stage Training Pipeline
DeepSeek's full pipeline consists of four key stages:
- Cold start fine-tuning with CoT data
- Reasoning-focused RL training (similar to R1-Zero)
- Rejection sampling to create new training data from the best outputs
- Final RL phase focused on both reasoning and general capabilities
The rejection sampling stage is particularly interesting - they use the partially trained model to generate responses, keep only the best ones, and combine them with data from DeepSeek-V3 covering areas like writing and factual Q&A.
Solving the Language Mixing Problem
One of R1-Zero's major issues was language inconsistency - often mixing multiple languages within a single solution. DeepSeek addressed this by:
- Adding a language consistency reward during RL training
- Measuring the proportion of target language words in responses
- Filtering out mixed-language examples during rejection sampling
While this slightly reduced raw performance metrics, it made the model's outputs much more usable in practice. The team found that this tradeoff between absolute performance and usability was worth making for a production model.
The results validate this approach - DeepSeek-R1 matches or exceeds OpenAI's o1-1217 across major benchmarks while maintaining consistent, readable outputs that better align with human preferences.
The Distillation Surprise
One of the most interesting findings in the DeepSeek paper isn't just about their main model - it's about how they managed to transfer its capabilities to much smaller models.
When they tried to apply their RL techniques directly to smaller models like Qwen-32B, the results weren't great. But when they instead distilled knowledge from the full DeepSeek-R1, something unexpected happened.
Direct RL vs Distillation
The team ran an experiment using Qwen-32B as a base model, comparing two approaches:
- Direct RL: Training for 10K steps using the same RL process as R1
- Distillation: Fine-tuning on 800K samples generated by DeepSeek-R1
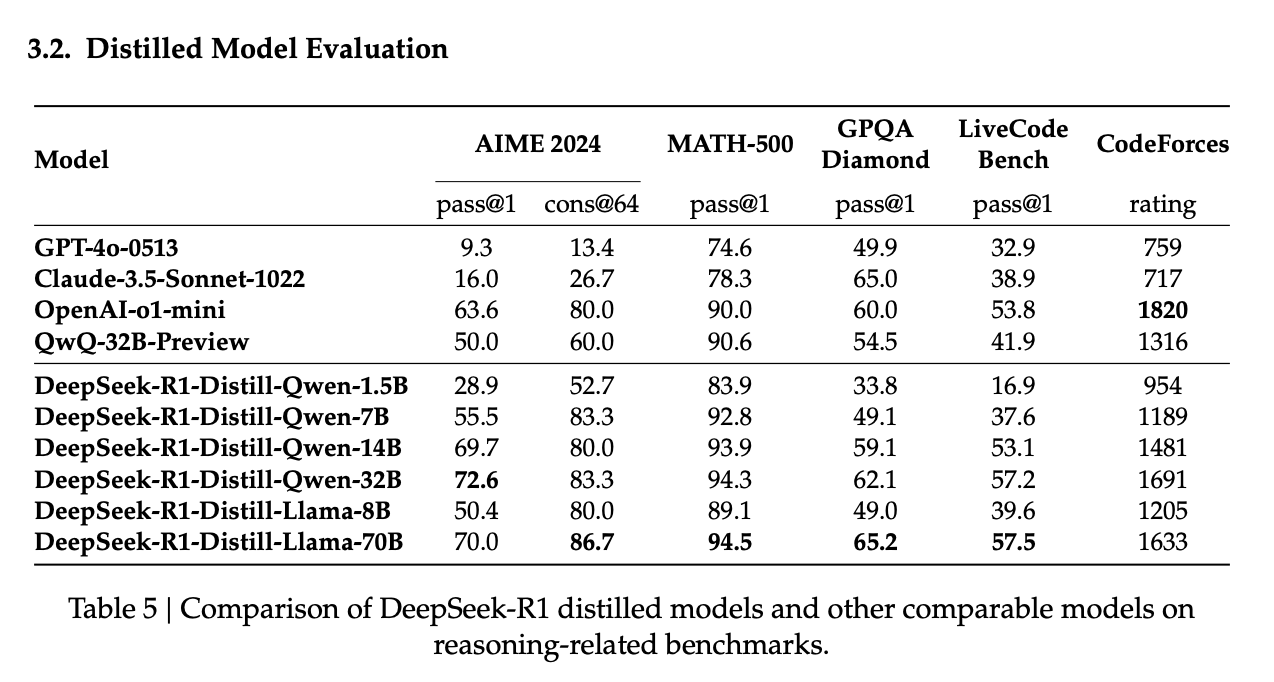
The results weren't even close. The distilled model significantly outperformed its RL-trained counterpart across all benchmarks:
- AIME 2024: 72.6% vs 47.0%
- MATH-500: 94.3% vs 91.6%
- LiveCodeBench: 57.2% vs 40.2%
Scaling Down Successfully
This success led them to try even smaller models. The results were impressive:
- Their 14B model outperformed QwQ-32B-Preview
- The 7B model achieved 55.5% on AIME 2024
- Even their tiny 1.5B model hit 28.9% on AIME, beating GPT-4o on certain tasks
What This Means for AI Development
These findings have major implications:
- Complex reasoning patterns discovered by larger models can be effectively compressed into smaller ones
- The path to better small models might be through distilling large ones rather than direct training
- Resource-intensive RL training might not be the best approach for smaller models
This suggests a potential new pipeline for developing efficient AI models: use expensive RL training only on large models, then distill those capabilities down to more practical sizes.
What Does Deepseek Mean for the AI Industry?
DeepSeek's R1 research opens up interesting paths forward for AI development. Let's break down what this means for the field.
Technical Training Implications
The success of R1 challenges some common assumptions about LLM training:
- Pure RL without supervised fine-tuning can develop sophisticated reasoning
- Simpler reward structures (just accuracy and format) can work better than complex ones
- Longer reasoning chains emerge naturally when models are given the freedom to develop them
- Distillation might be more effective than direct RL for smaller models
The Compute Question
While NVIDIA and other chip stocks took a hit on news about R1's training requirements, the reality is more nuanced:
- The initial R1-Zero training uses less compute than traditional SFT→RL pipelines
- The full R1 model's multi-stage approach is more compute-intensive
- Distillation provides an efficient path to smaller models
- The 32B distilled model achieves 72.6% AIME accuracy with significantly less compute than full-scale training
Future Directions and Limitations
DeepSeek identifies several key areas for improvement:
- General capabilities still lag behind DeepSeek-V3 for tasks like function calling and complex role-playing
- Language mixing remains a challenge, especially for non-English/Chinese languages
- The model is sensitive to prompting - few-shot examples actually hurt performance
- Software engineering tasks need better evaluation pipelines for RL training
Most importantly, the paper suggests that improving base model capabilities might be more crucial than post-training techniques. Their success with distillation implies that the reasoning patterns discovered by larger models are crucial for improving overall AI capabilities.
Looking ahead, this research suggests we might see a shift toward:
- More focused use of RL for specific capabilities like reasoning
- Better distillation techniques to make models more efficient
- New approaches to combine the benefits of SFT and pure RL
- More emphasis on base model architecture and pre-training
Summary: Deepseek R1
DeepSeek R1 is undoubtedly a major breakthrough in AI reasoning capabilities through a novel pure RL approach. Their initial R1-Zero showed that models can develop sophisticated reasoning without supervised fine-tuning, while the full R1 model refined this with a multi-stage pipeline to create a more production-ready system.
While initial reports suggested DeepSeek R1 trained on just $5.5M of compute (compared to GPT-4's estimated $100M+), the actual costs are likely higher when including the full pipeline and distillation experiments. Regardless, R1's approach points to a more nuanced future for GPU demand.
The real story isn't about using less compute overall, but using it more effectively. Companies are still going to significant GPU resources for:
- Training the initial large models that make distillation possible
- Running multiple distillation experiments to optimize smaller models
- Serving these models at scale in production
DeepSeek's breakthrough is more about training efficiency than reducing compute needs. In my opinion, instead of reducing GPU demand, this research suggests companies will be investing heavily in compute - just with a sharper focus on efficient RL-based training techniques and knowledge transfer between models.
Further Resources
- Paper: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- GitHub: Deepseek




