

In our previous ChatGPT Plugin tutorials, we've been working on building plugins that either call a third-party APIs or building simple API functionality ourselves.
In this guide, we'll expand on this and walk through how to setup the the open source ChatGPT Retrieval Plugin, which:
...provides a flexible solution for semantic search and retrieval of personal or organizational documents using natural language queries.
For this project, the data I'll use will be scraped from each page of this website, which will then be split into smaller subsections of text, and the embeddings will be computed with OpenAI Embeddings API and stored at Pinecone.
With the embeddings stored at a vector database, the retrieval plugin will be able to fetch up-to-date information about AI and machine learning from my site and answer questions past its cutoff date of September 2021.
In case you're unfamiliar with vector databases, as Pinecone highlights:
...vector embeddings are a type of data representation that carries within it semantic information that’s critical for the AI to gain understanding and maintain a long-term memory they can draw upon when executing complex tasks.
In order to integrate Pinecone and long-term memory into our ChatGPT Plugin, the steps we'll need to take include:
- Setting Up the Retrieval Plugin in Replit
- Storing Vector Embeddings at Pinecone
- Testing the Query API Endpoint
- Deploying the ChatGPT Retrieval Plugin
- Using the Retrieval Plugin in ChatGPT
1. Setting Up the ChatGPT Retrieval Plugin in Replit
To get started, we can setup the retreival plugin as follows.
1.1 Clone the Repository
Let's start by forking the ChatGPT Retrieval Plugin Github repo to create a copy that we can work with.
1.2: Create a new Replit
Next up, let's go and create a new Python Replit and import the Github repo we just cloned:
1.3: Setup Replit Environment
Next we need to setup our Replit environemnt with the necessary installs:
- Install poetry:
pip install poetry - Create a new virtual environment with Python 3.10:
poetry env use python3.10 - Activate the virtual environment:
poetry shell
1.4: Set Environment Variables
After that, let's go and setup our environment variables, in this case we can add them into Replit's builtin Secrets Manager:
- Open your Replit project and click on the "Secrets" icon
- Click on the "Add new secret" button.
- For this project, we'll add the following secrets for this project:
DATASTORE=pineconeBEARER_TOKEN="jwt.io_generated_token"OPENAI_API_KEY="your_api_key"PINECONE_API_KEY="your_api_key"PINECONE_ENVIRONMENT="your_pinecone_env"PINECONE_INDEX="your_pinecone_index"
Note that you can create a new BEARER_TOKEN from jwt.io, which provides JSON web tokens, for example:
2. Storing Vector Embeddings at Pinecone
We've covered how to compute and store embeddings at Pinecone in previous articles, so we won't cover it in-depth here.That said, here's an overview of what we need to do:
- Data collection: Here we want to either crawl a website or create a folder with your desired docs, notes, codebase, etc.
- Data preprocessing: In most cases, for this step we want to split the text into chunks with of a maximum number of tokens so that we don't run into token limit issues when retrieving this context and feeding it to our ChatGPT Plugin.
- Compute embeddings: In this step, we use the Embeddings API from OpenAI to compute the embeddings of our text.
- Storing the embeddings at Pinecone: Lastly, we need to upsert our computed embeddings and store them at Pinecone
You can find the previous articles we've written that go through each of these steps in detail below:
 Peter Foy
Peter Foy Peter Foy
Peter Foy
As the ChatGPT retrieval plugin repo highlights:
Make sure to use a dimensionality of 1536 for the embeddings and avoid indexing on the text field in the metadata, as this will reduce the performance significantly.
In order to upsert out embeddings, we first need to:
- Convert of prepared DataFrame to a list of dictionaries
- Iterate over the list and prepares the data in the format expected by Pinecone & the ChatGPT Retrieval Plugin, which is a tuple containing the ID, embeddings, and metadata
- Finally, we upsert the data to Pinecone in batches of 100
import pinecone
from tqdm.auto import tqdm
# Initialize the Pinecone connection
pinecone.init(api_key=PINECONE_API_KEY, environment=PINECONE_API_ENV)
index_name = 'mlqassistant'
# Check if the index already exists, and if not, create it
if index_name not in pinecone.list_indexes():
pinecone.create_index(index_name, dimension=1536, metric='dotproduct')
# Connect to the index
index = pinecone.Index(index_name)
# Convert the DataFrame to a list of dictionaries
chunks = df.to_dict(orient='records')
to_upsert = []
for chunk in tqdm(chunks):
uid = chunk['id']
embeds = chunk['embeddings']
meta = {
'title': chunk['title'],
'url': chunk['url'],
'text': chunk['text'] # Add the 'text' field to the metadata
}
to_upsert.append((uid, embeds, meta))
batch_size = 100
for i in tqdm(range(0, len(to_upsert), batch_size)):
i_end = min(len(to_upsert), i + batch_size)
batch = to_upsert[i:i_end]
index.upsert(vectors=batch)
# View index stats
index.describe_index_stats()3. Testing the Query API Endpoint
Now that we've got our embeddings stored at Pinecone and our ChatGPT Retrieval Plugin prepared at Replit, we can go and test out the query as follows:
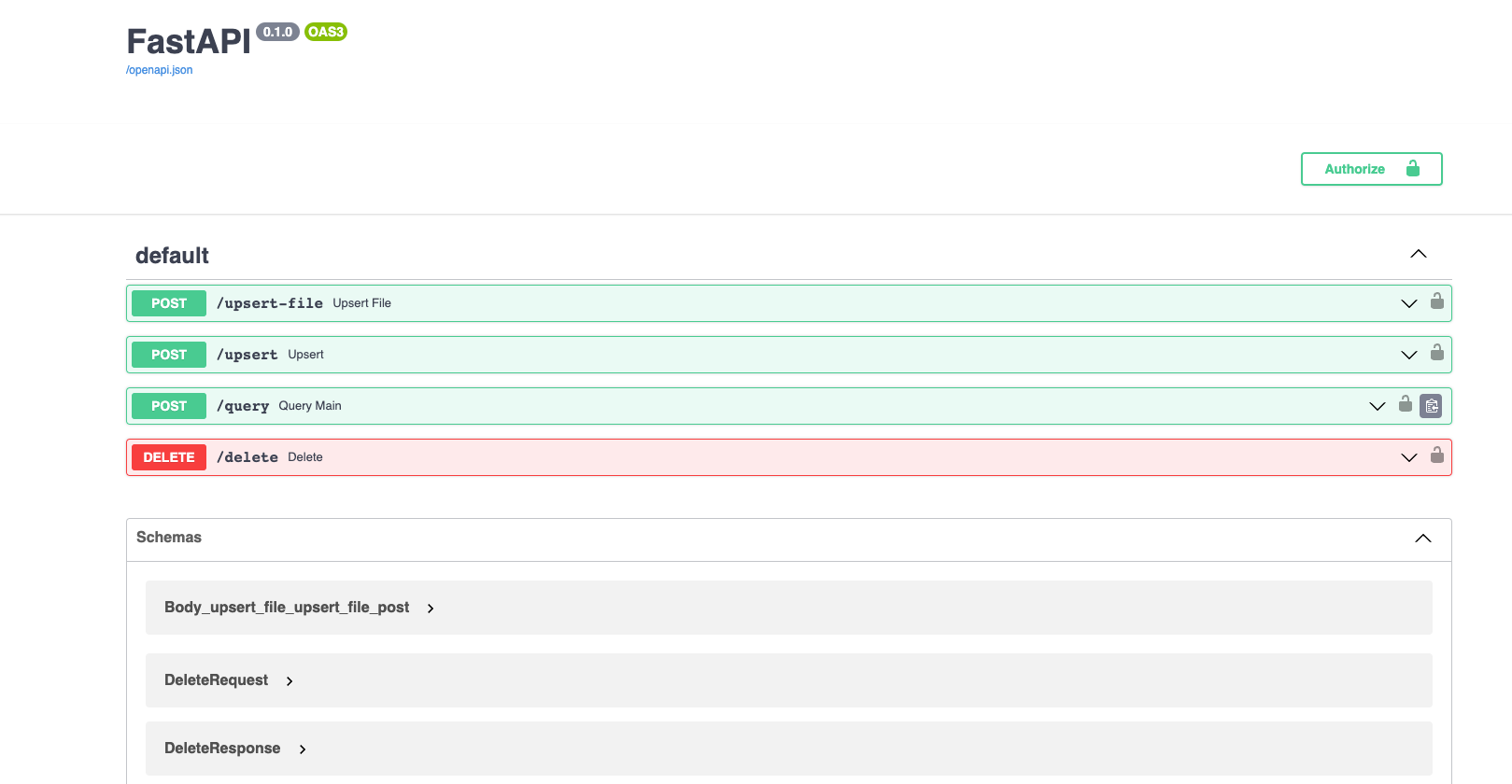
- Run the API in the Replit terminal with
poetry run start - Navigate to https://your-replit-project.username.repl.co/docs and you should see:
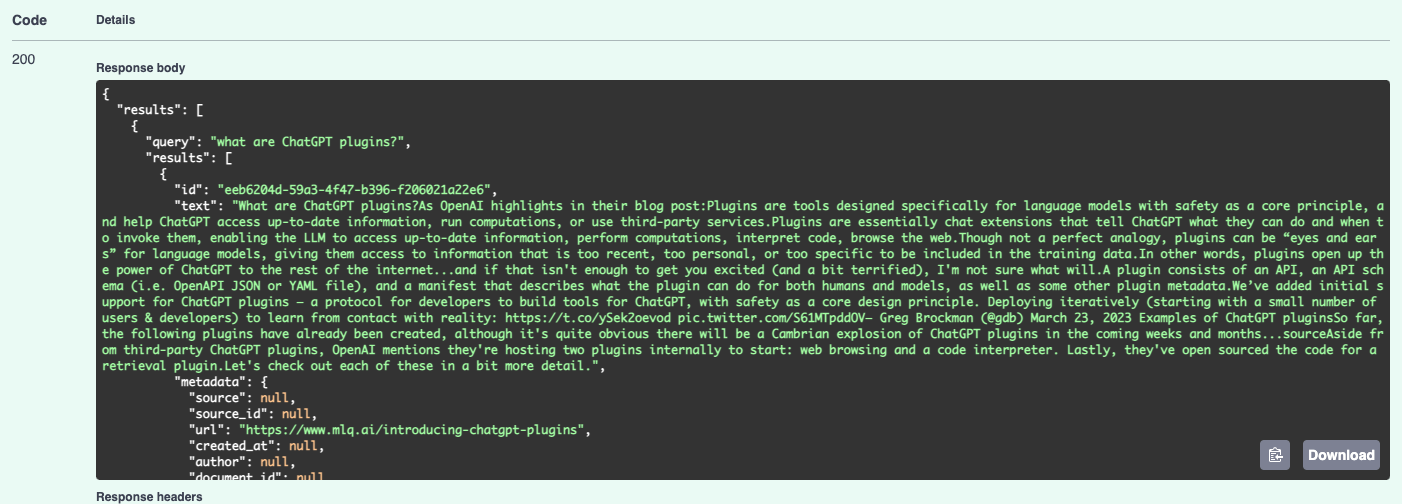
We can also test out the query endpoint in and see if it's correctly retrieving context from my site, for example after I authorize with my bearer token, I can test out the following query: "What are ChatGPT plugins?":
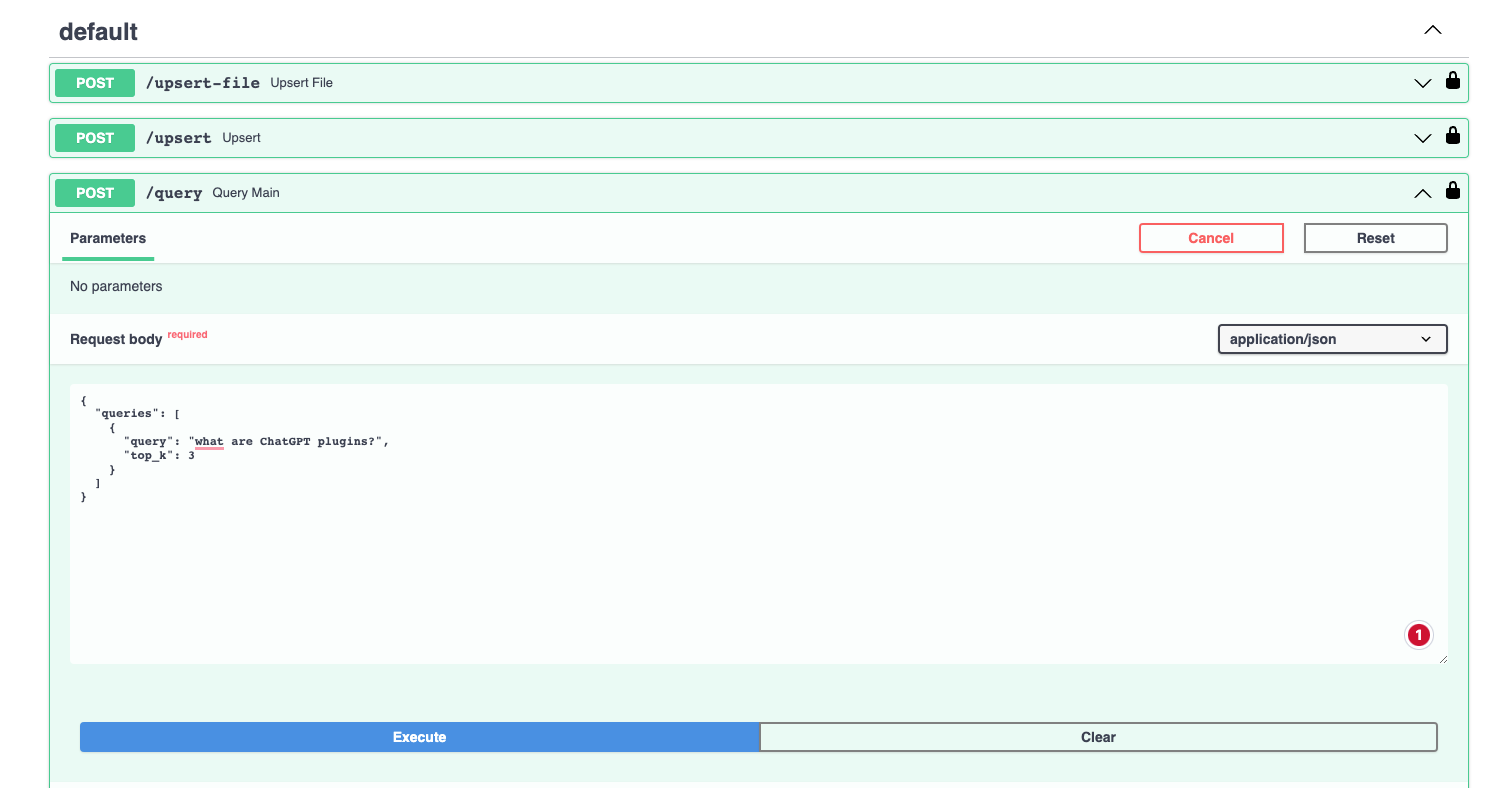
Here we can see the endpoint is now retrieving the top 3 relevant results from my vector database:
4. Deploying the ChatGPT Retrieval Plugin
Alright now that we know the query endpoint is working, the steps we need to take to deploy this include:
4.1. Update the ai-plugin.json URL
Update the ai-plugin.json located within the .well-known folder with your Replit URL in the api section and logo.
Here you can also modify the description_for_model to tell ChatGPT when and how to use this plugin, for example:
{
"schema_version": "v1",
"name_for_model": "MLQassistant",
"name_for_human": "MLQ Assistant",
"description_for_model": "Use this tool to get up-to-date information on AI and machine learning from the site MLQ.ai. If users ask questions about AI and machine learning, answer the question and use the retrieved context provide relevant links if applicable." ,
"description_for_human": "Master AI & machine leanring with MLQ.ai.",
"auth": {
"type": "user_http",
"authorization_type": "bearer"
},
"api": {
"type": "openapi",
"url": "https://chatgpt-retrieval-plugin.mlqai.repl.co/.well-known/openapi.yaml",
"has_user_authentication": false
},
"logo_url": "https://chatgpt-retrieval-plugin.mlqai.repl.co/.well-known/logo.png",
"contact_email": "hello@contact.com",
"legal_info_url": "hello@legal.com"
}4.2: Update the openapi.yaml file
Next, you'll just need to add the same Replit URL to the server: - url section:
openapi: 3.0.2
info:
title: Retrieval Plugin API
description: A retrieval API for querying and filtering documents based on natural language queries and metadata
version: 1.0.0
servers:
- url: https://chatgpt-retrieval-plugin.mlqai.repl.co
paths:
#...rest of the code5. Using the Retrieval Plugin in ChatGPT
With those two files updated, we're now ready to go and test the Retrieval plugin in ChatGPT. The steps we need to take to do this include:
- Run the API with
poetry run startif it's not already running - Go to ChatGPT Plugin store, click "Develop your own plugin", add your Replit URL and install it
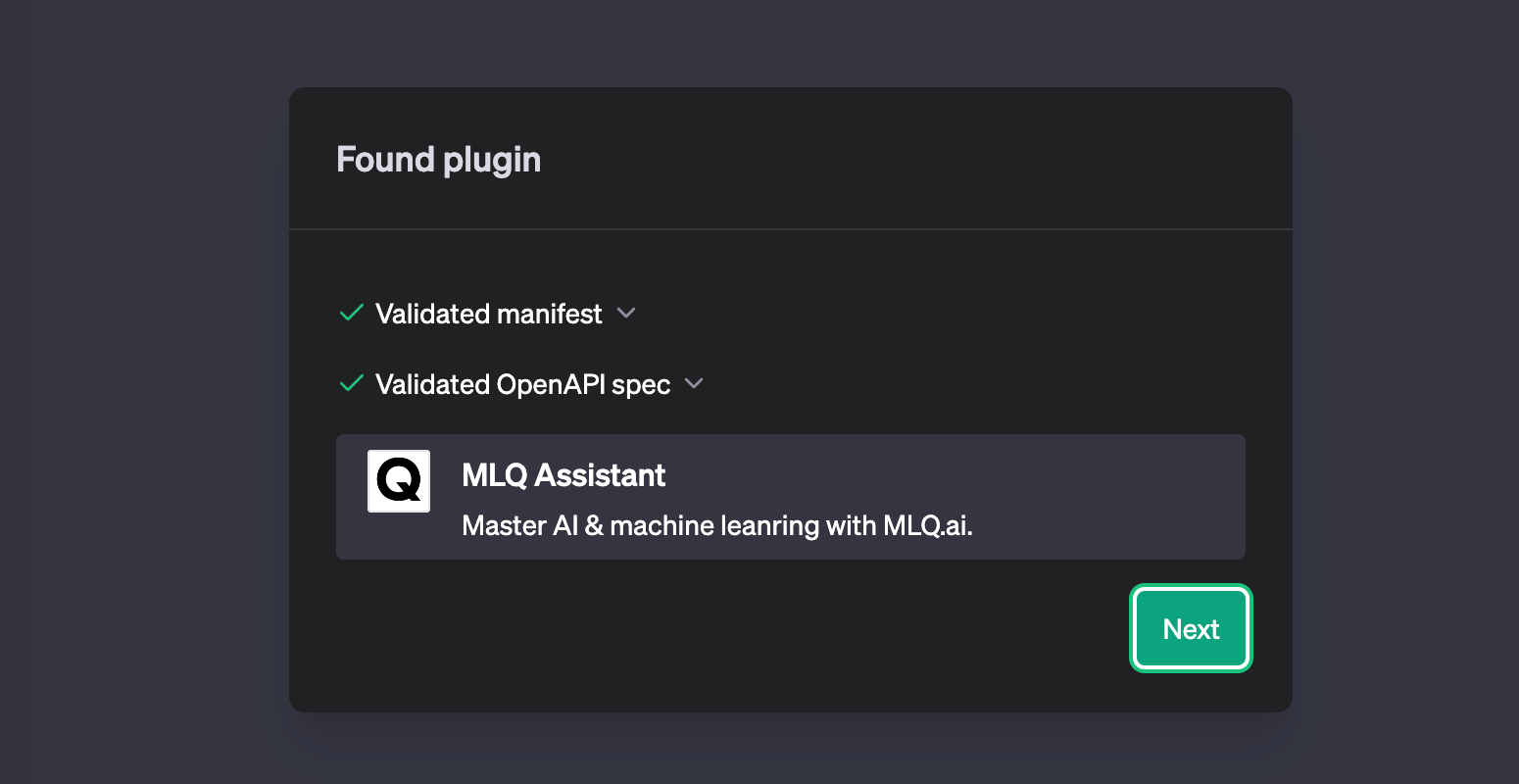
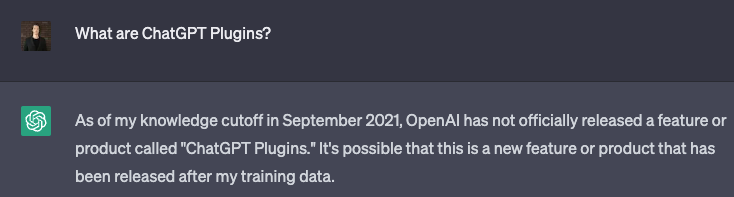
After adding our bearer token for authorization, I can now test it out by asking a question about a recent AI/ML topic that I've written about and I know ChatGPT doesn't have access to on it's own...first, let's test wihtout the plugins.
Now, after we enable the new plugin, it should be able to retrieve relevant context from my site and answer the question...
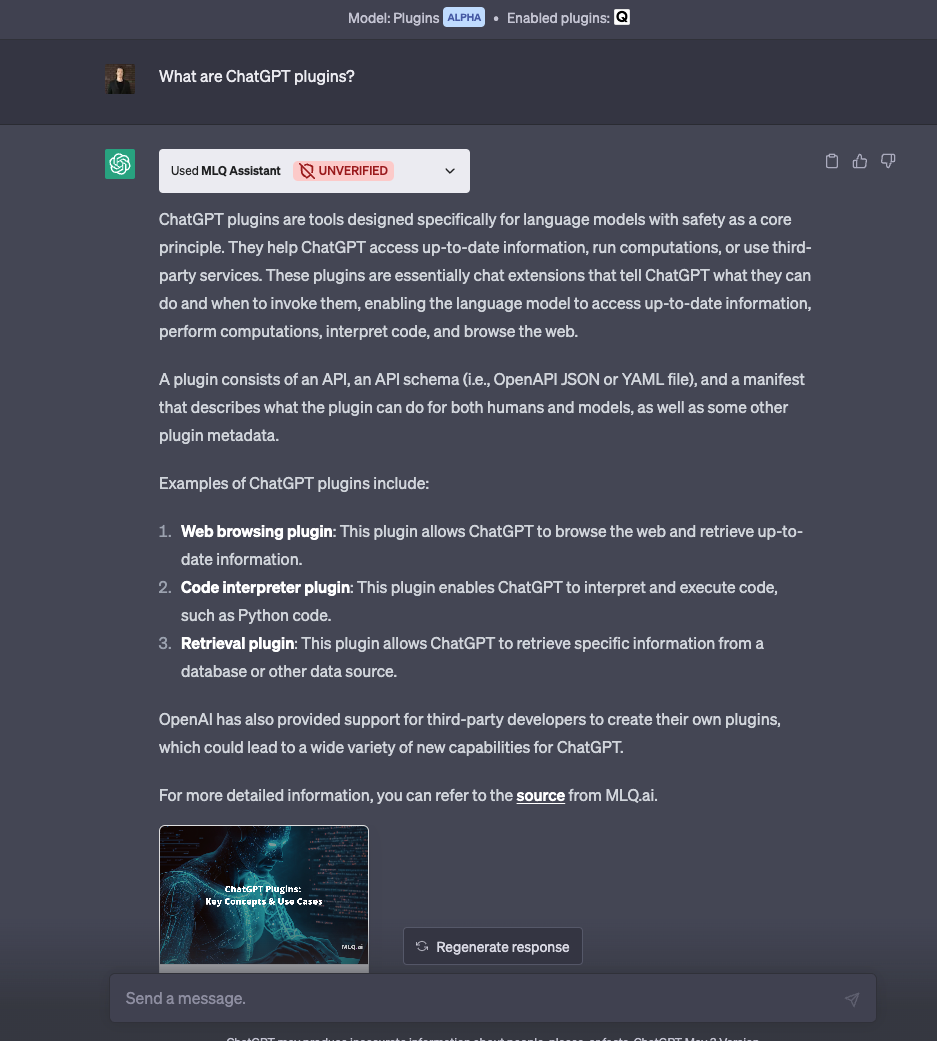
Success! I can now see from the API call that's it's able to respond accurately and provides relevant resources.
Summary: Getting Started with the ChatGPT Retrieval Plugin
In this guide, we saw how to get started with adding long term memory to ChatGPT plugins using the open source retrieval plugin and a vector database like Pinecone.
So far we've only experimented with the /query parameter in the plugin, although we can also add and delete files to our database with the following endpoints
/upsert: Upload one or more documents and store their text and metadata in the vector database./upsert-file: Upload a single file (PDF, TXT, DOCX, PPTX, or MD) and store its text and metadata in the vector database./delete: Delete documents from the vector database using their IDs, a metadata filter, or adelete_allflag
For now, we've got V1 of our retrieval plugin project setup, and in the next few articles we'll discuss how we can improve it with some additional functionality.




