

Spreadsheets are ubiquitous tools for data management and analysis, but until now their structure has posed challenges for large language models (LLMs).
This week, however, Microsoft researchers released a new paper called SpreadsheetLLM: Encoding Spreadsheets for Large Language Models.
This study introduced SpreadsheetLLM, which is a novel framework enabling LLMs to understand and reason across spreadsheet data with unprecedented effectiveness.
We introduce SpreadsheetLLM, pioneering an efficient encoding method designed to unleash and optimize LLMs' powerful understanding and reasoning capability on spreadsheets.
In this AI paper summary, we'll look at the key findings, implications, and takeaways.
SpreadsheetLLM: Key Takeaways
- SpreadsheetLLM is a novel framework that allows large language models to effectively process and understand spreadsheet data.
- The framework includes SheetCompressor, an encoding method that compresses spreadsheets by up to 25 times while preserving essential information.
- SpreadsheetLLM achieves state-of-the-art performance in spreadsheet table detection, outperforming previous methods by a significant margin.
- The research introduces Chain of Spreadsheet (CoS), a new approach for tackling complex spreadsheet tasks like question answering.
- The framework demonstrates strong potential for enhancing AI-powered data analysis and user interactions with spreadsheets.
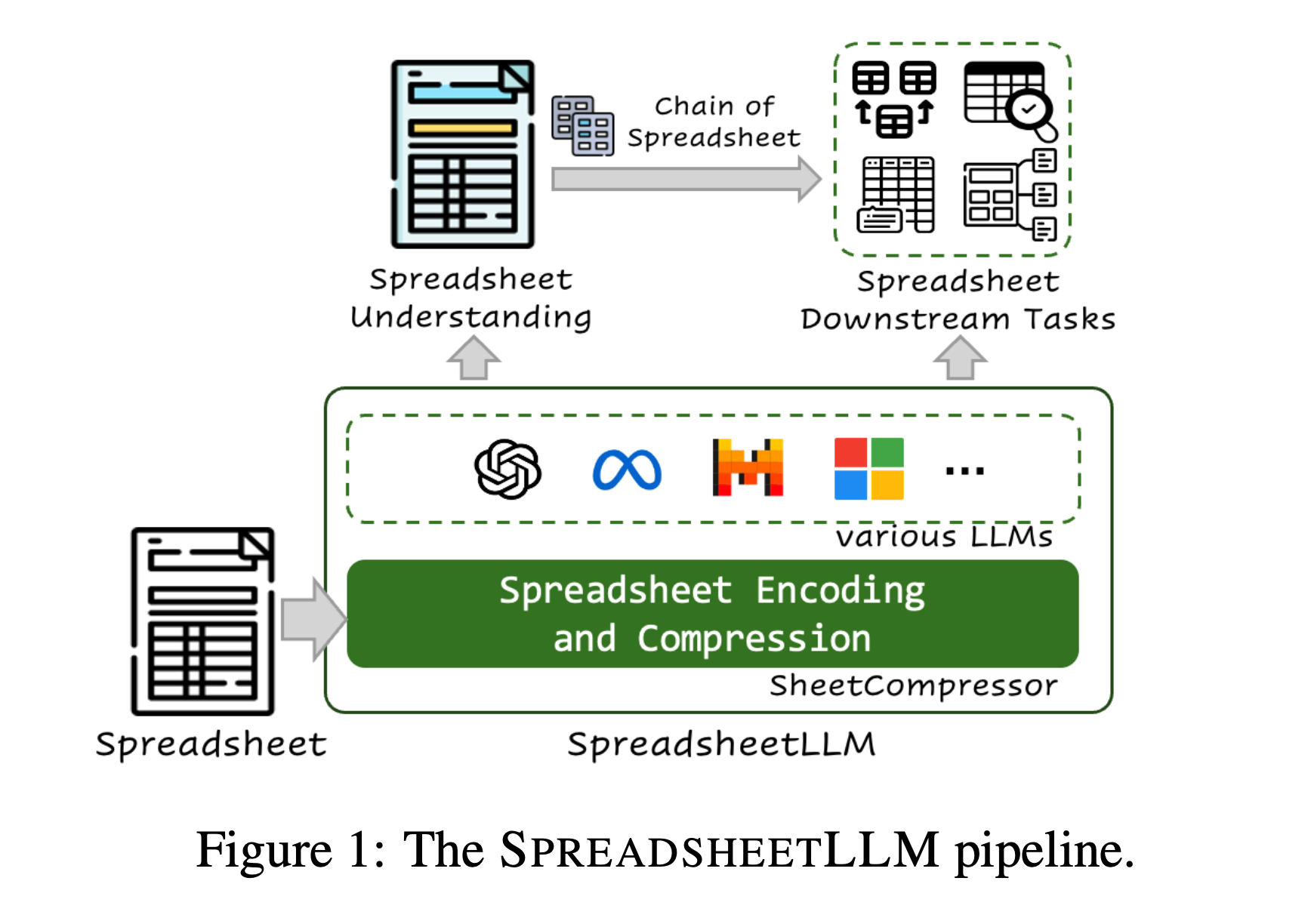
Research Methodology
The researchers developed SpreadsheetLLM through a multi-step approach:
- They created a novel encoding method called SheetCompressor, which compresses spreadsheet data efficiently while retaining crucial structural and semantic information.
- SheetCompressor employs three key modules: structural-anchor-based compression, inverse index translation, and data-format-aware aggregation.
- The team fine-tuned various large language models, including GPT-4 and open-source alternatives, on spreadsheet understanding tasks.
- They introduced Chain of Spreadsheet (CoS), a two-stage process for breaking down complex spreadsheet tasks into more manageable steps.
- The framework was evaluated on spreadsheet table detection and question answering tasks, using carefully curated datasets and rigorous testing protocols.
SpreadsheetLLM: Findings
Here are a few key findings from this research:
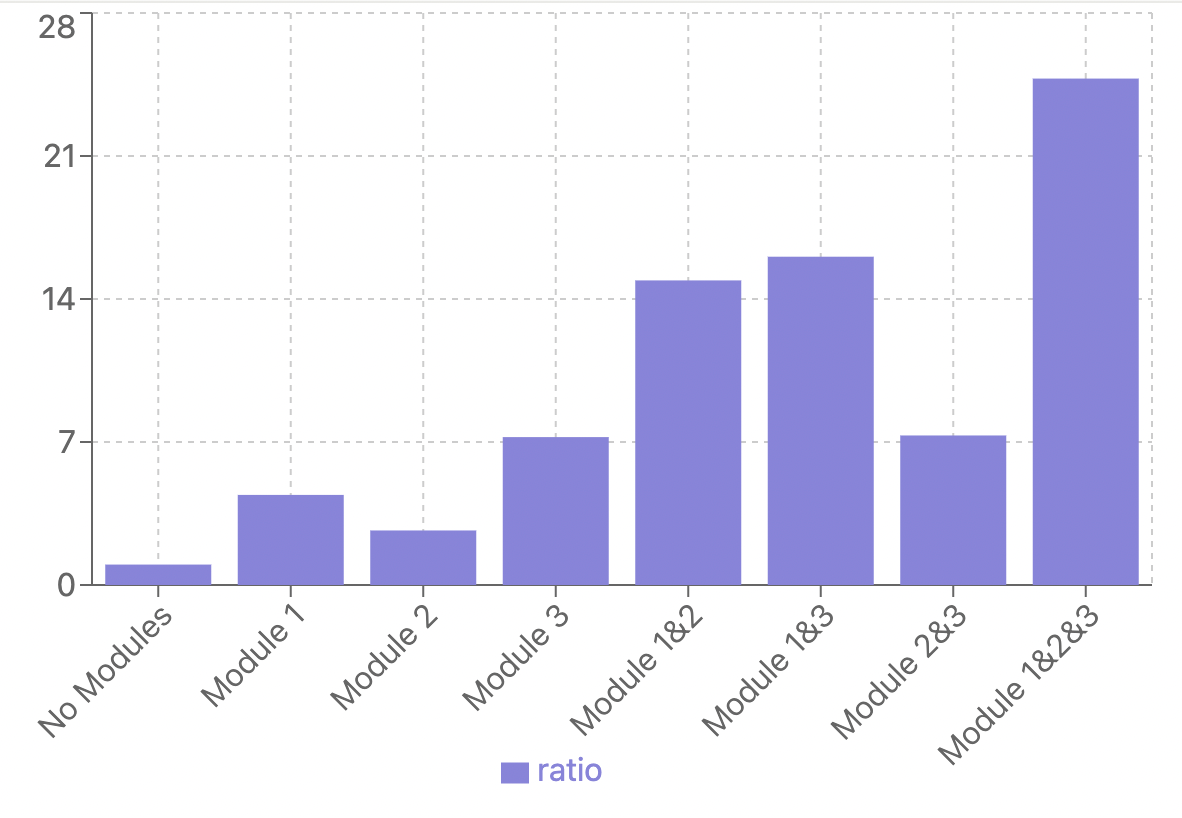
- Compression Efficiency: SheetCompressor achieved an impressive 25x compression ratio on test datasets, significantly reducing the computational load for processing large spreadsheets.
Below is a compression ratio comparison and present a bar chart showing compression ratios for different SheetCompressor modules. This was generated by MLQ.ai and not the paper.
- Table Detection Performance: SpreadsheetLLM set a new state-of-the-art in spreadsheet table detection:
- The fine-tuned GPT-4 model achieved an F1 score of 78.9%, surpassing the previous best method by 12.3%.
- Open-source models like Llama3 and Mistral-v2 also showed strong performance, reaching F1 scores of around 72%.
Below is a chart for table detection performance across spreadsheet sizes. Specifically it shows a line graph showing F1 scores for different models across spreadsheet sizes. This was generated by MLQ.ai and not the paper.
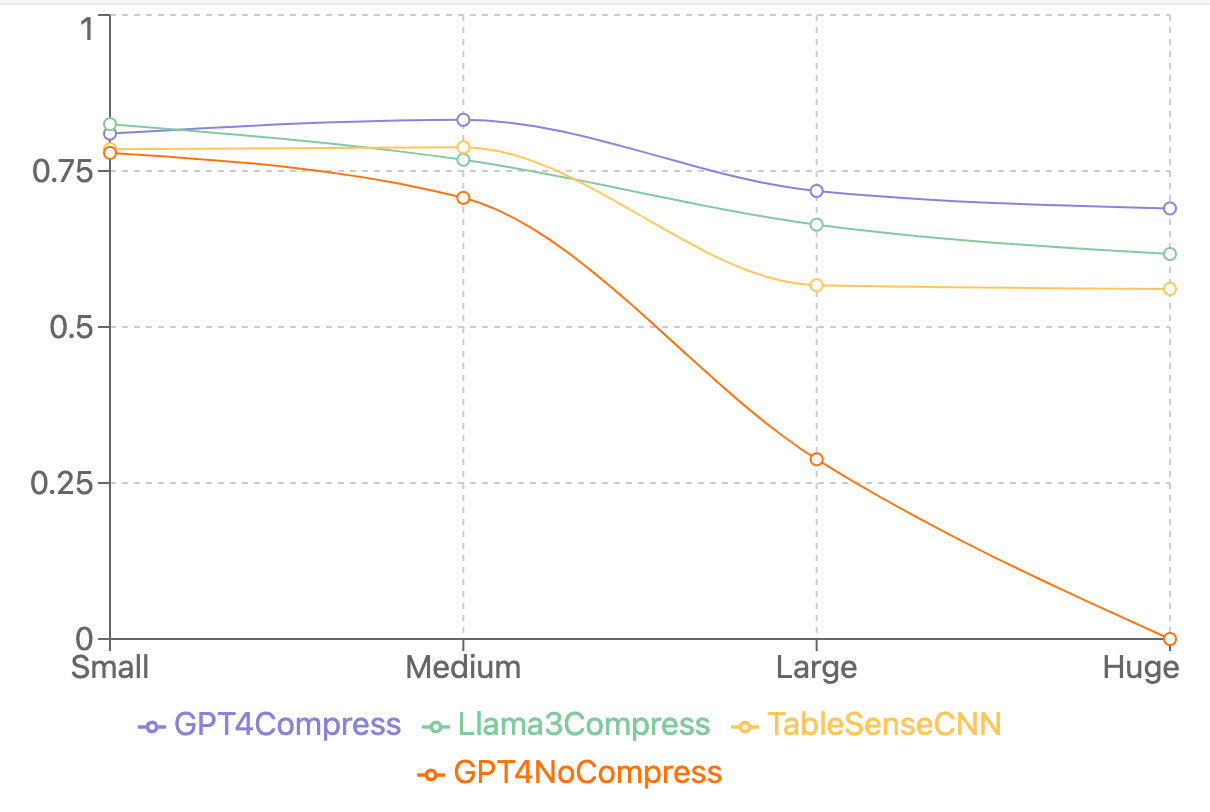
- Handling Large Spreadsheets: The framework demonstrated remarkable improvements in processing larger spreadsheets, with F1 score increases of up to 75% on huge spreadsheets compared to baseline models.
- Question Answering Capabilities: In spreadsheet QA tasks, SpreadsheetLLM outperformed existing methods:
- It achieved an accuracy of 74.3% when fine-tuned on table detection tasks.
- This represents 37% and 12% improvements over TAPEX and Binder models, respectively.
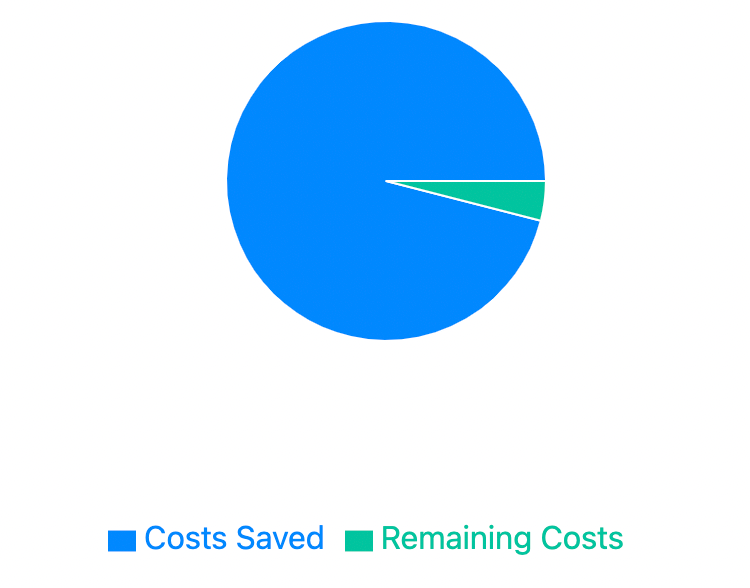
- Cost Reduction: The compression techniques led to a 96% reduction in processing costs for models like GPT-3.5 and GPT-4, making large-scale spreadsheet analysis more economically viable.
Below is a chart on cost reduction with SpreadsheetLLM we created, specifically a pie chart showing the costs saved: 96% (deep blue) and remaining costs: 4% (light blue). This was generated by MLQ.ai and not the paper.
Implications of SpreadsheetLLM
The SpreadsheetLLM framework has far-reaching implications for AI-powered data analysis and business-related tasks with spreadsheets:
- Enhanced Data Understanding: AI systems can now better interpret complex spreadsheet structures, potentially leading to more accurate and insightful automated analysis
- Improved AI Assistants: The framework could enable more sophisticated AI assistants for spreadsheet software, helping users with tasks like data cleaning, analysis, and visualization.
- Cost-Effective Large-Scale Analysis: The significant reduction in processing costs makes it feasible to apply advanced AI techniques to massive spreadsheet datasets in business and research contexts.
- Bridging AI and Traditional Data Tools: This research helps narrow the gap between cutting-edge AI capabilities and widely-used data management tools, potentially accelerating the adoption of AI in various industries.
- Foundation for Future Research: SpreadsheetLLM provides a solid base for further developments in AI-powered spreadsheet understanding, potentially leading to even more advanced capabilities in the future.
Summary: SpreadsheetLLM
While spreadsheets, math, and other complex analysis tasks have long been a challenge for LLMs, SpreadsheetLLM represents a significant breakthrough in enabling AI systems to understand and reason about spreadsheet data.
By addressing the challenges of spreadsheet complexity and size, this research opens up new possibilities for AI-powered data analysis and user assistance.
The framework's impressive performance in table detection and question-answering tasks, coupled with its efficient compression techniques, paves the way for more sophisticated and cost-effective spreadsheet analysis at scale.
For our focus on at MLQ.ai AI for finance and investing, breakthroughs like SpreadsheetLLM have the potential to massively reduce the time it takes to extract insights from spreadsheet data, bridging the gap between traditional data tools and large language models.




